
安装云平台环境.md 25 KB
[TOC]
1、安装前的准备工作
1.1、准备三台服务器
虚拟机的最低标准 master 至少4核心 内存至少8G 存储空间80G以上 node 至少2核心 内存至少4G 存储空间60G以上
需要准备三台服务器并设置静态IP,这里不再赘述。本文档的配置如下
| 节点名称 | ip |
|---|---|
| master | 192.168.238.20 |
| node1 | 192.168.238.21 |
| node2 | 192.168.238.22 |
1.2、安装前的准备工作
# 关闭防火墙
systemctl stop firewalld && systemctl disable firewalld
# 关闭selinux
sed -i 's/enforcing/disabled/' /etc/selinux/config # 永久
setenforce 0 # 临时
cat /etc/selinux/config
# 关闭swap
swapoff -a # 临时
sed -ri 's/.*swap.*/#&/' /etc/fstab # 永久
free -m
# 根据规划设置主机名
hostnamectl set-hostname <hostname>
# 在master添加hosts
cat >> /etc/hosts << EOF
192.168.238.20 master
192.168.238.21 node1
192.168.238.22 node2
EOF
# 将桥接的IPv4流量传递到iptables的链
cat > /etc/sysctl.d/k8s.conf << EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
sysctl --system # 生效
# 修改当前时间为北京时间
# 查看当前系统时间
date
# 修改当前系统时间
date -s "2018-2-22 19:10:30
# 查看硬件时间
hwclock --show
# 修改硬件时间
hwclock --set --date "2018-2-22 19:10:30"
# 同步系统时间和硬件时间
hwclock --hctosys
# 保存时钟
clock -w
上述操作执行完毕后重启
reboot
三台服务器,开始下一步的安装
2、离线安装Docker及其相应组件(三台服务机都需要安装)
2.1、离线安装Docker
# 1.创建目录存放相应的安装包
mkdir -p /opt/package/docker
# 2.上传安装包下的docker文件夹到上述的目录中
# 3.进入目录,进行解压缩操作
cd /opt/package/docker
unzip docker19-rpm.zip
# 4.安装docker
rpm -ivh *.rpm --force --nodeps
systemctl enable docker && systemctl start docker
# 5.查看是否安装成功
docker --version
输出docker版本号表示安装成功

2.2、离线安装Docker-compose
将安装包目录下的docker-compose-linux-x86_64文件上传到服务机的/opt/package目录下使用命令
// 1.将下载好的文件传入linux系统中,并重命名未docker-compose
mv docker-compose-linux-x86_64 docker-compose
// 2.给予docker-compose文件可执行权限
chmod u+x docker-compose
// 3.将docker-compose文件移至/usr/local/bin
mv docker-compose /usr/local/bin
// 4.查看版本
docker-compose --version
输出docker-compose版本号表示安装成功

3、安装Harbor及相应的配置(只需要一台服务机安装)
3.0、安装注意事项
本文档Harbor安装在单独一台虚拟机上面,如果只有三台机器,请将下面的server.harbor.com换成固定的IP(这里的固定IP意思是安装harbor的虚拟机的IP),例如将harbor仓库安装在master节点就将server.harbor.com换为192.168.238.20。
3.1、安装Harbor
将压缩包harbor-offline-installer-v2.1.5.tgz上传到
/opt/package/目录下
- 解压该压缩包
sh tar xf harbor-offline-installer-v2.1.5.tgz
- 解压该压缩包
修改harbor安装的配置文件
首先备份一份压缩包
# 复制配置文件内容到harbor.yml 中(安装时只识别harbor.yml)
cp harbor.yml.tmpl harbor.yml
# 用于存放harbor的持久化数据
mkdir -p /opt/package/harbor/data
# 用于存放harbor的日志
mkdir -p /opt/package/harbor/log
其次对harbor.yml文件进行修改配置
# 需要修改为域名,如果没有单独的机器,请修改为IP
hostname: server.harbor.com
# http related config
http:
port: 80
# 需要全部注释
# https related config
# https:
# https port for harbor, default is 443
# port: 443
# The path of cert and key files for nginx
# certificate: /your/certificate/path
# private_key: /your/private/key/path
data_volume: /opt/package/harbor/data # 需要添加一个自己的目录
log:
location: /opt/package/harbor/log # 需要添加一个自己的目录
- 安装并启动Harbor
保证此时在harbor安装文件中,执行install.sh文件进行安装,命令为:
./install.sh
- 访问harbor Web界面
通过自己的ip+端口访问

3.2、配置Docker访问Harbor(三台服务机都要配置)
首先修改服务机的hosts,如果没有单独的harbor服务器,请忽略这一步
# 将下面的ip缓存harbor的ip
echo "10.168.59.60 server.harbor.com">> /etc/hosts
docker添加harbor配置-----注意这里要加harbor的端口号,这里配置的端口号为上述harbor配置文件的端口号
mkdir -p /etc/docker
tee /etc/docker/daemon.json <<-'EOF'
{
"insecure-registries": ["server.harbor.com:80"]
}
EOF
systemctl daemon-reload && systemctl restart docker
# 如果是ip方式
mkdir -p /etc/docker
tee /etc/docker/daemon.json <<-'EOF'
{
"insecure-registries": ["192.168.238.20:80", "192.168.238.20", "lab3", "la"]
}
EOF
systemctl daemon-reload && systemctl restart docker
输入命令
# 重新启动harbor,因为docker重启但是harbor不能自动重启
cd /opt/package/
docker-compose start
# 登录harbor
docker login server.harbor.com:80
输入用户名:admin
密码:Harbor12345
 至此,harbor配置完成
至此,harbor配置完成
4、K8S 离线安装及NFS配置(三台服务机都需要安装)
4.1 、上传kube1.9.0.tar.gz(以下简称kube1.9)到服务器
# 1.三台服务机创建目录
mkdir -p /opt/package/k8s
# 2.上传文件到指定目录
scp -r kube1.9.0.tar.gz root@192.168.238.20:/opt/package/k8s
scp -r kube1.9.0.tar.gz root@192.168.238.21:/opt/package/k8s
scp -r kube1.9.0.tar.gz root@192.168.238.22:/opt/package/k8s
4.2 、解压安装主从
# 1.master下,进入/opt/package/k8s目录下解压,执行脚本
tar -zxvf kube1.19.0.tar.gz
cd kube/shell
chmod +x init.sh
./init.sh
# 2.等待init.sh执行完毕,之后执行
chmod +x master.sh
./master.sh
# 3. node1和node2执行下面的命令
cd /opt/package/k8s
tar -zxvf kube1.9.0.tar.gz
cd kube/shell
chmod +x init.sh
./init.sh
# 4. 进入master节点将/etc/kubernetes/admin.conf文件复制到node1节点和node2节点
scp -r /etc/kubernetes/admin.conf node1:/etc/kubernetes/
scp -r /etc/kubernetes/admin.conf node2:/etc/kubernetes/
4.3 、从节点加入主节点
在master节点生成token
kubeadm token create --print-join-command效果如下
[root@master shell]# kubeadm token create --print-join-command W1009 17:15:31.782757 37720 configset.go:348] WARNING: kubeadm cannot validate component configs for API groups [kubelet.config.k8s.io kubeproxy.config.k8s.io] kubeadm join 192.168.0.90:6443 --token ul68zs.dkkvpwfex9rpzo0d --discovery-token-ca-cert-hash sha256:3e3ee481f5603621f216e707321aa26a68834939e440be91322c62eb8540ffce- 在node1和node2中执行下面的命令------注意这里要上面生产的命令
kubeadm join 192.168.0.90:6443 --token ul68zs.dkkvpwfex9rpzo0d --discovery-token-ca-cert-hash sha256:3e3ee481f5603621f216e707321aa26a68834939e440be91322c62eb8540ffce结果如下
[root@node1 shell]# kubeadm join 192.168.0.90:6443 --token ul68zs.dkkvpwfex9rpzo0d --discovery-token-ca-cert-hash sha256:3e3ee481f5603621f216e707321aa26a68834939e440be91322c62eb8540ffce [preflight] Running pre-flight checks [WARNING IsDockerSystemdCheck]: detected "cgroupfs" as the Docker cgroup driver. The recommended driver is "systemd". Please follow the guide at https://kubernetes.io/docs/setup/cri/ [WARNING FileExisting-socat]: socat not found in system path [preflight] Reading configuration from the cluster... [preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -oyaml' [kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml" [kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env" [kubelet-start] Starting the kubelet [kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap... This node has joined the cluster: * Certificate signing request was sent to apiserver and a response was received. * The Kubelet was informed of the new secure connection details. Run 'kubectl get nodes' on the control-plane to see this node join the cluster.给node1和node2添加执行权限
# 在node1和node2执行一下命令
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
kubectl get nodes
# 注意上面的admin.conf是从master节点复制过来的
4.4、 验证集群pod是否running,各节点是否ready
watch kubectl get pod -n kube-system -o wide 效果如下
[root@master shell]# watch kubectl get pod -n kube-system -o wide
Every 2.0s: kubectl get pod -n kube-system -o wide Fri Oct 9 17:45:03 2020
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
calico-kube-controllers-5d7686f694-94fcc 1/1 Running 0 48m 100.89.161.131 master <none> <none>
calico-node-42bwj 1/1 Running 0 48m 192.168.0.90 master <none> <none>
calico-node-k6k6d 1/1 Running 0 27m 192.168.0.189 node2 <none> <none>
calico-node-lgwwj 1/1 Running 0 29m 192.168.0.68 node1 <none> <none>
coredns-f9fd979d6-2ncmm 1/1 Running 0 48m 100.89.161.130 master <none> <none>
coredns-f9fd979d6-5s4nw 1/1 Running 0 48m 100.89.161.129 master <none> <none>
etcd-master 1/1 Running 0 48m 192.168.0.90 master <none> <none>
kube-apiserver-master 1/1 Running 0 48m 192.168.0.90 master <none> <none>
kube-controller-manager-master 1/1 Running 0 48m 192.168.0.90 master <none> <none>
kube-proxy-5g2ht 1/1 Running 0 29m 192.168.0.68 node1 <none> <none>
kube-proxy-wpf76 1/1 Running 0 27m 192.168.0.189 node2 <none> <none>
kube-proxy-zgcft 1/1 Running 0 48m 192.168.0.90 master <none> <none>
kube-scheduler-master 1/1 Running 0 48m 192.168.0.90 master <none> <none>
kubectl get nodes 效果如下
[root@master shell]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master Ready master 22m v1.19.0
node1 Ready <none> 2m17s v1.19.0
node2 Ready <none> 24s v1.19.0
4.5、配置NFS
| master | NFS服务端+NFS客户端 |
|---|---|
| node1 | NFS客户端 |
| node2 | NFS客户端 |
- 将本地nfs离线包上传至服务器及各个节点的/opt/package/nfs文件夹下
scp -r nfs master:/opt/package
scp -r nfs node1:/opt/package
scp -r nfs n:/opt/package
- 安装服务端(master节点操作)
# 进入master节点内/opt/package/nfs文件夹内执行以下命令
# 进入/opt/package/nfs
cd /opt/package/nfs
# 安装nfs
rpm -ivh *.rpm --force --nodeps # 注意如果不能安装选择 nfs.zip文件
# 执行命令 vi /etc/exports,创建 exports 文件,文件内容如下:
echo "/nfs/data/ *(insecure,rw,sync,no_root_squash)" > /etc/exports
# 执行以下命令,启动 nfs 服务
# 创建共享目录
mkdir -p /nfs/data
systemctl enable rpcbind
systemctl enable nfs-server
systemctl start rpcbind
systemctl start nfs-server
exportfs -r
# 检查配置是否生效
exportfs
# 输出结果如下所示
/nfs/data <world>
安装NFS客户端(三台服务机操作)
# 进入node1,node2节点内/opt/package/nfs文件夹内执行以下命令 cd /opt/package/nfs rpm -ivh *.rpm --force --nodeps # 注意如果不能安装选择 nfs.zip文件 systemctl start nfs && systemctl enable nfsK8S中安装NFS(任意K8S节点,这里选择master节点) ```sh
1.进入/opt/package/nfs目录
cd /opt/package/nfs
2.载入docker镜像
docker load < nfs-client-provisioner.tar.gz
3.修改deployment.yaml文件
vim /opt/package/nfs/deployment.yaml
apiVersion: apps/v1 kind: Deployment metadata: name: nfs-client-provisioner labels: app: nfs-client-provisioner
replace with namespace where provisioner is deployed
namespace: default spec: replicas: 1 strategy: type: Recreate selector: matchLabels: app: nfs-client-provisioner template: metadata: labels:
app: nfs-client-provisionerspec: serviceAccountName: nfs-client-provisioner containers:
- name: nfs-client-provisioner image: quay.io/external_storage/nfs-client-provisioner:latest ##默认是latest版本 imagePullPolicy: Never ## 这里选择从本地拉取 volumeMounts: - name: nfs-client-root mountPath: /persistentvolumes env: - name: PROVISIONER_NAME value: fuseim.pri/ifs - name: NFS_SERVER value: 192.168.238.20 ##这里写NFS服务器的IP地址 - name: NFS_PATH value: /nfs/data ##这里写NFS服务器中的共享挂载目录(强调:这里的路径必须是目录中最后一层的文件夹,否则部署的应用将无权限创建目录导致Pending)volumes:
- name: nfs-client-root nfs: server: 192.168.238.20 ##这里写NFS服务器的IP地址 path: /nfs/data ##NFS服务器中的共享挂载目录(强调:这里的路径必须是目录中最后一层的文件夹,否则部署的应用将无权限创建目录导致Pending)4、部署yaml文件
[root@k8s-client nfs]# kubectl apply -f .
5、查看服务
[root@k8s-client nfs]# kubectl get pods NAME READY STATUS RESTARTS AGE nfs-client-provisioner-
78697f488-5p52r 1/1 Running 0 16h6、列出你的集群中的StorageClass
[root@k8s-client nfs]# kubectl get storageclass NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE managed-nfs-storage fuseim.pri/ifs Delete Immediate false 16h
7、标记一个StorageClass为默认的 (是storageclass的名字也就是你部署的StorageClass名字是啥就写啥)
[root@k8s-client nfs]# kubectl patch storageclass managed-nfs-storage -p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"true"}}}' storageclass.storage.k8s.io/managed-nfs-storage patched
8、验证你选用为默认的StorageClass
[root@k8s-client nfs]# kubectl get storageclass NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE managed-nfs-storage (default) fuseim.pri/ifs Delete Immediate false
```
5、安装kubesphere及其相应的插件
5.1、将离线包上传至harbor仓库(该操作只需在master节点进行)
将安装包目录下的kubesphere文件夹上传至服务机master节点的
/opt/package/
目录下
进入harbor仓库
 新建一个kubesphere项目
新建一个kubesphere项目

# 在服务机master节点中执行命令
# 重新启动harbor,因为docker重启但是harbor不能自动重启
cd /opt/package/harbor
docker-compose start
# 进入该路径
cd /opt/package/kubesphere/
# 上传安装包 这里的最后一行改成自己harbor仓库的ip+端口号+项目名称
chmod +x offline-installation-tool.sh
./offline-installation-tool.sh -l images-list.txt -d ./kubesphere-images -r server.harbor.com:80/kubesphere
# 等待上传完毕

5.2、最小化安装kubesphere
# 执行以下命令
# 1.编辑cluster-configuration.yaml添加您的私有镜像仓库
vim cluster-configuration.yaml
spec:
persistence:
storageClass: ""
authentication:
jwtSecret: ""
local_registry: server.harbor.com:80/kubesphere #添加内容
# 2.编辑完成后保存 cluster-configuration.yaml,使用以下命令将 ks-installer 替换为您自己仓库的地址---(本文的harbor安装地址server.harbor.com:80/kubesphere)
sed -i "s#^\s*image: kubesphere.*/ks-installer:.*# image: server.harbor.com:80/kubesphere/kubesphere/ks-installer:v3.1.1#" kubesphere-installer.yaml
# 3.请按照如下先后顺序安装(必须)
kubectl apply -f kubesphere-installer.yaml
kubectl get pods -A


# 4.等待ks-installer容器运行完毕,执行
kubectl apply -f cluster-configuration.yaml
5.3、检查安装日志
# 检查安装日志等待安装成功
kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l app=ks-install -o jsonpath='{.items[0].metadata.name}') -f
如下图所示,则表示安装成功

5.4、安装必要的插件
本次需要安装额外的几个插件
- KubeSphere日志系统
- KubeSphere DevOps
- KubeSphere kubeedge
# 1.编辑cluster-configuration.yaml
vim cluster-configuration.yaml
devops:
enabled: true # 将“false”更改为“true”。
kubeedge:
enabled: true # 将“false”更改为“true”。
logging:
enabled: true # 将“false”更改为“true”。
# 2.执行以下命令开始安装
kubectl apply -f cluster-configuration.yaml
# 3.监控安装过程
kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l app=ks-install -o jsonpath='{.items[0].metadata.name}') -f
如下图所示,表示安装成功


5.5、开放30881端口(重要--master节点操作)
kubectl -n kubesphere-system patch svc ks-apiserver -p '{"spec":{"type":"NodePort","ports":[{"port":80,"protocal":"TCP","targetPort":9090,"nodePort":30881}]}}'

5.6、创建云平台的企业空间
- 登录kubesphere,输入http://10.168.59.60:30880/,端口号默认为30880,第一次进入需要修改初始密码为: MKcloud123

- 进入企业空间,创建新的企业空间为mkcloud

- 进入企业空间mkcloud,创建项目mkcloud
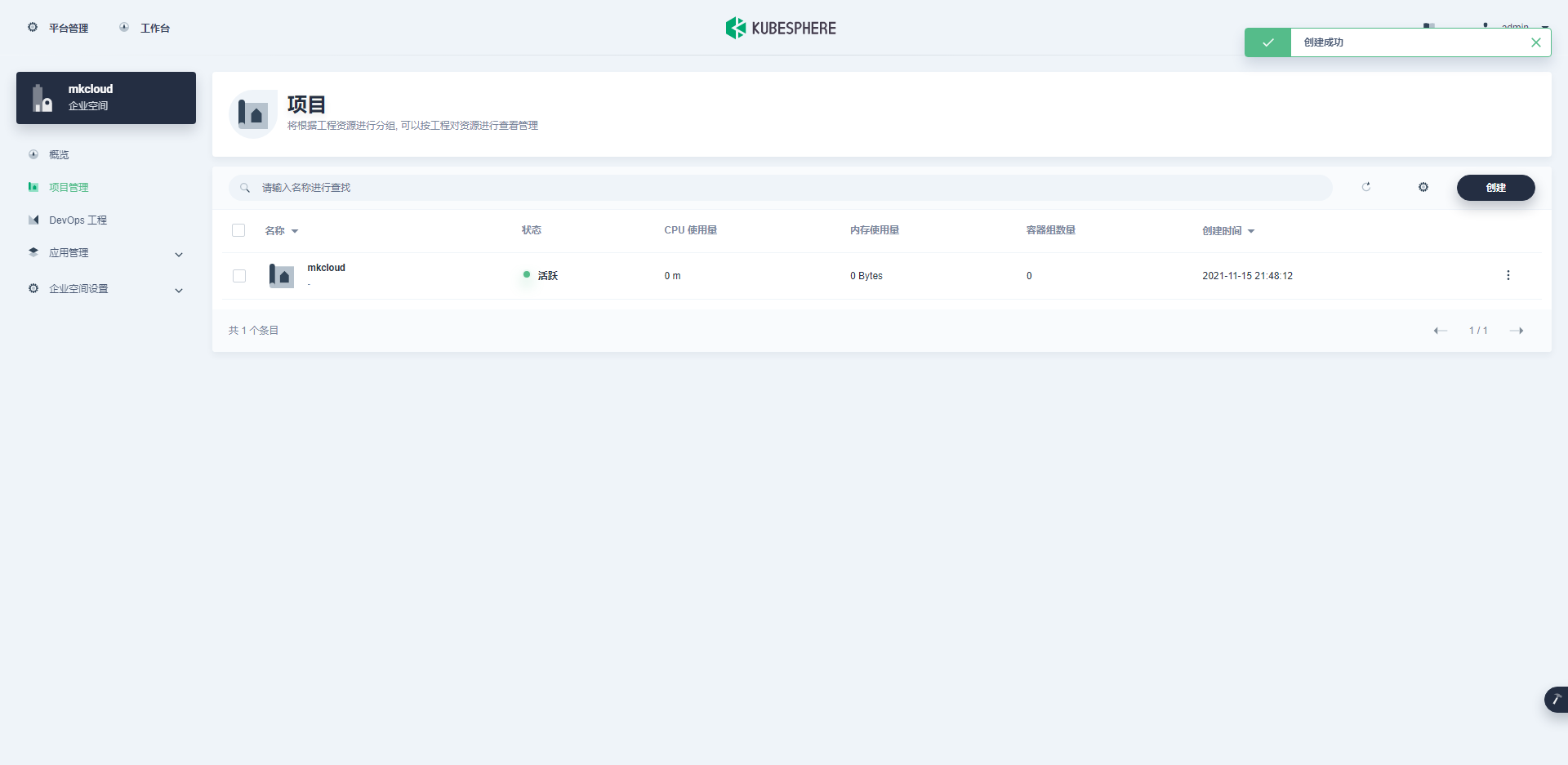
- 进入项目选择默认设置即可
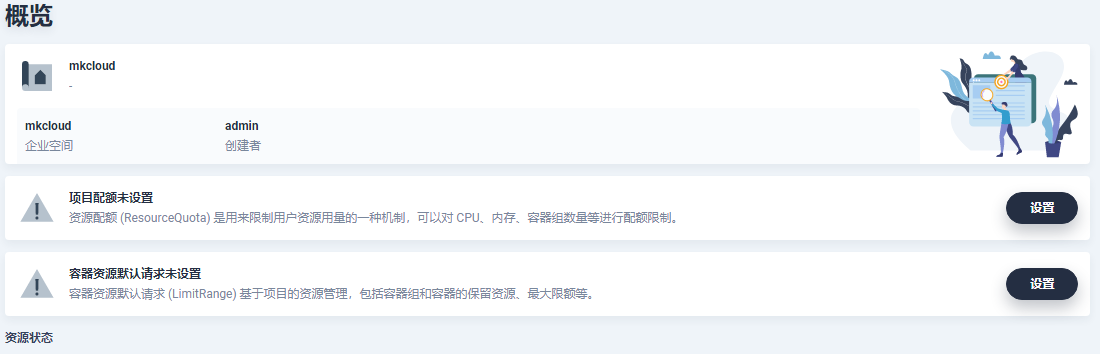

5.7、kubesphere添加Harbor仓库
- 进入当前项目
- 选择配置中心的密钥,选择添加密钥

- 密钥名称填写为harbor,仓库地址填写域名加端口号

- 添加成功会显示私有密钥

6、卸载云平台环境
6.1、卸载K8S
kubeadm reset -f
modprobe -r ipip
lsmod
rm -rf ~/.kube/
rm -rf /etc/kubernetes/
rm -rf /etc/systemd/system/kubelet.service.d
rm -rf /etc/systemd/system/kubelet.service
rm -rf /usr/bin/kube*
rm -rf /etc/cni
rm -rf /opt/cni
rm -rf /var/lib/etcd
rm -rf /var/etcd
yum clean all
yum remove kube*
6.2、卸载docker
# 1.停止docker
sudo systemctl stop docker
# 2.查询安装过的包
yum list installed | grep docker
# 3.删除安装的软件包
yum -y remove docker*
# 4.删除镜像/容器等
rm -rf /var/lib/docker
7、目前遇见的BUG与解决方案
7.1、harbor仓库登录显示400错误

Error response from daemon: login attempt to https://server.harbor.com/v2/ failed with status: 400 Bad Request
查询相关文档发现是nginx的配置出现了问题 Docker 登录返回 400 错误请求
#修改方式如下
#1.进入harbor仓库位置
cd /opt/package/software/harbor
#2.修改配置文件
vim ./common/config/portal/nginx.conf
#3.增加一个字段
http {
client_body_temp_path /tmp/client_body_temp;
proxy_temp_path /tmp/proxy_temp;
fastcgi_temp_path /tmp/fastcgi_temp;
uwsgi_temp_path /tmp/uwsgi_temp;
scgi_temp_path /tmp/scgi_temp;
large_client_header_buffers 4 1k; #增加的
#4.重启nginx即可
docker ps
#执行的结果e939b007b6ca goharbor/harbor-core:v2.3.2 "/harbor/entrypoint.…"
docker restart e39629e9c2c4
7.2、单节点安装pod报错Pending

# 当创建单机版的 k8s 时,这个时候 master 节点是默认不允许调度 pod 的,需要执行
kubectl taint nodes --all node-role.kubernetes.io/master-
7.3、kubesphere的api-server无法启动
api-server显示报错---无法申请资源,原因是docker的进程数不够,增加一下的配置重启docker就行
echo "
[Unit]
Description=Docker Application Container Engine
Documentation=https://docs.docker.com
# BindsTo=containerd.service
# After=network-online.target firewalld.service containerd.service
After=network-online.target firewalld.service
Wants=network-online.target
# Requires=docker.socket
[Service]
Type=notify
# the default is not to use systemd for cgroups because the delegate issues still
# exists and systemd currently does not support the cgroup feature set required
# for containers run by docker
# ExecStart=/usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock
ExecStart=/usr/local/bin/dockerd
ExecReload=/bin/kill -s HUP $MAINPID
TasksMax=infinity
TimeoutSec=0
RestartSec=2
Restart=always
# Note that StartLimit* options were moved from "Service" to "Unit" in systemd 229.
# Both the old, and new location are accepted by systemd 229 and up, so using the old location
# to make them work for either version of systemd.
StartLimitBurst=3
# Note that StartLimitInterval was renamed to StartLimitIntervalSec in systemd 230.
# Both the old, and new name are accepted by systemd 230 and up, so using the old name to make
# this option work for either version of systemd.
StartLimitInterval=60s
# Having non-zero Limit*s causes performance problems due to accounting overhead
# in the kernel. We recommend using cgroups to do container-local accounting.
LimitNOFILE=infinity
LimitNPROC=infinity
LimitCORE=infinity
# Comment TasksMax if your systemd version does not support it.
# Only systemd 226 and above support this option.
# TasksMax=infinity
# set delegate yes so that systemd does not reset the cgroups of docker containers
Delegate=yes
# kill only the docker process, not all processes in the cgroup
KillMode=process
[Install]
WantedBy=multi-user.target
" > /etc/systemd/system/docker.service
# 重启docker
systemctl daemon-reload && systemctl restart docker
7.4、k8s cgroup 内存泄漏
centos7.6及其以下版本,造成内存泄漏
vim /boot/grub2/grub.cfg
# 在 ro crashkernel=auto 后面添加 cgroup.memory=nokmem
# 重启电脑

附录----安装软件的版本
| 软件 | 版本 |
|---|---|
| centos | 7.7 |
| docker | 19.03.7 |
| docker-compose | 2.1.0 |
| Harbor | 2.1.5 |
| kubernetes | 1.19.0 |
| kubesphere | 3.1.1 |