
docker.md 19 KB
什么是docker
说实话关于 Docker 是什么并太好说,下面我通过四点向你说明 Docker 到底是个什么东西。
- Docker 是世界领先的软件容器平台。
- Docker 使用 Google 公司推出的 Go 语言 进行开发实现,基于 Linux 内核 提供的 CGroup 功能和 namespace 来实现的,以及 AUFS 类的 UnionFS 等技术,对进程进行封装隔离,属于操作系统层面的虚拟化技术。 由于隔离的进程独立于宿主和其它的隔离的进程,因此也称其为容器。
- Docker 能够自动执行重复性任务,例如搭建和配置开发环境,从而解放了开发人员以便他们专注在真正重要的事情上:构建杰出的软件。
- 用户可以方便地创建和使用容器,把自己的应用放入容器。容器还可以进行版本管理、复制、分享、修改,就像管理普通的代码一样。
Docker 容器的特点
- 轻量 : 在一台机器上运行的多个 Docker 容器可以共享这台机器的操作系统内核;它们能够迅速启动,只需占用很少的计算和内存资源。镜像是通过文件系统层进行构造的,并共享一些公共文件。这样就能尽量降低磁盘用量,并能更快地下载镜像。
- 标准 : Docker 容器基于开放式标准,能够在所有主流 Linux 版本、Microsoft Windows 以及包括 VM、裸机服务器和云在内的任何基础设施上运行。
- 安全 : Docker 赋予应用的隔离性不仅限于彼此隔离,还独立于底层的基础设施。Docker 默认提供最强的隔离,因此应用出现问题,也只是单个容器的问题,而不会波及到整台机器。
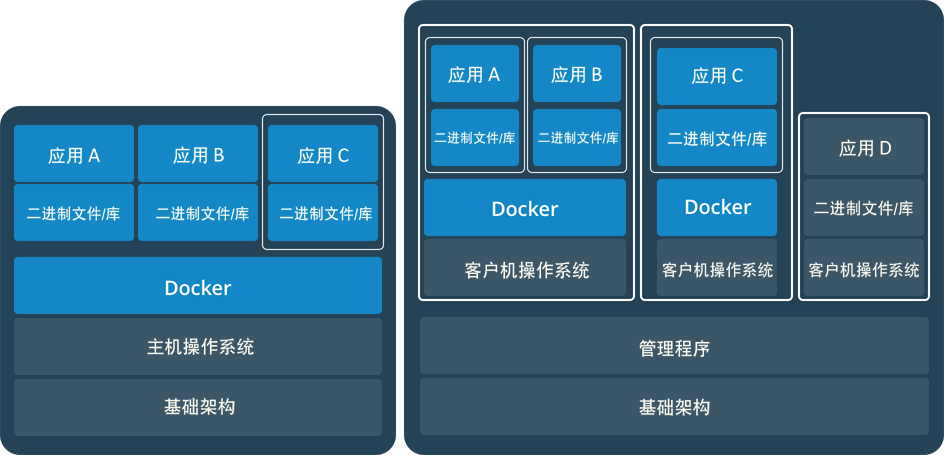
docker和虚拟机对比
传统虚拟机技术是虚拟出一套硬件后,在其上运行一个完整操作系统,在该系统上再运行所需应用进程;而容器内的应用进程直接运行于宿主的内核,容器内没有自己的内核,而且也没有进行硬件虚拟。因此容器要比传统虚拟机更为轻便。


- 容器是一个应用层抽象,用于将代码和依赖资源打包在一起。 多个容器可以在同一台机器上运行,共享操作系统内核,但各自作为独立的进程在用户空间中运行 。与虚拟机相比, 容器占用的空间较少(容器镜像大小通常只有几十兆),瞬间就能完成启动 。
- 虚拟机 (VM) 是一个物理硬件层抽象,用于将一台服务器变成多台服务器。 管理程序允许多个 VM 在一台机器上运行。每个 VM 都包含一整套操作系统、一个或多个应用、必要的二进制文件和库资源,因此 占用大量空间 。而且 VM 启动也十分缓慢 。
通过 Docker 官网,我们知道了这么多 Docker 的优势,但是大家也没有必要完全否定虚拟机技术,因为两者有不同的使用场景。虚拟机更擅长于彻底隔离整个运行环境。例如,云服务提供商通常采用虚拟机技术隔离不同的用户。而 Docker 通常用于隔离不同的应用 ,例如前端,后端以及数据库。
就我而言,对于两者无所谓谁会取代谁,而是两者可以和谐共存。
docker底层原理
Docker 技术是基于 LXC(Linux container- Linux 容器)虚拟容器技术的。
LXC,其名称来自 Linux 软件容器(Linux Containers)的缩写,一种操作系统层虚拟化(Operating system–level virtualization)技术,为 Linux 内核容器功能的一个用户空间接口。它将应用软件系统打包成一个软件容器(Container),内含应用软件本身的代码,以及所需要的操作系统核心和库。通过统一的名字空间和共用 API 来分配不同软件容器的可用硬件资源,创造出应用程序的独立沙箱运行环境,使得 Linux 用户可以容易的创建和管理系统或应用容器。
LXC 技术主要是借助 Linux 内核中提供的 CGroup 功能和 namespace 来实现的,通过 LXC 可以为软件提供一个独立的操作系统运行环境。
cgroup 和 namespace 介绍:
namespace 是 Linux 内核用来隔离内核资源的方式。 通过 namespace 可以让一些进程只能看到与自己相关的一部分资源,而另外一些进程也只能看到与它们自己相关的资源,这两拨进程根本就感觉不到对方的存在。具体的实现方式是把一个或多个进程的相关资源指定在同一个 namespace 中。Linux namespaces 是对全局系统资源的一种封装隔离,使得处于不同 namespace 的进程拥有独立的全局系统资源,改变一个 namespace 中的系统资源只会影响当前 namespace 里的进程,对其他 namespace 中的进程没有影响。
CGroup 是 Control Groups 的缩写,是 Linux 内核提供的一种可以限制、记录、隔离进程组 (process groups) 所使用的物力资源 (如 cpu memory i/o 等等) 的机制。
cgroup 和 namespace 两者对比:
两者都是将进程进行分组,但是两者的作用还是有本质区别。namespace 是为了隔离进程组之间的资源,而 cgroup 是为了对一组进程进行统一的资源监控和限制。
namespace
每个进程在 Linux 系统中都拥有自己的命名空间(namespace).Namespace是对全局系统资源的一种封装隔离,使得处于不同namespace的进程拥有独立的全局系统资源,改变一个namespace中的系统资源只会影响当前namespace里的进程,对其他namespace中的进程没有影响。
Linux内核支持的namespaces
目前,Linux内核里面实现了7种不同类型的namespace。
名称 宏定义 隔离内容
Cgroup CLONE_NEWCGROUP Cgroup root directory (since Linux 4.6)
IPC CLONE_NEWIPC System V IPC, POSIX message queues (since Linux 2.6.19)
Network CLONE_NEWNET Network devices, stacks, ports, etc. (since Linux 2.6.24)
Mount CLONE_NEWNS Mount points (since Linux 2.4.19)
PID CLONE_NEWPID Process IDs (since Linux 2.6.24)
User CLONE_NEWUSER User and group IDs (started in Linux 2.6.23 and completed in Linux 3.8)
UTS CLONE_NEWUTS Hostname and NIS domain name (since Linux 2.6.19)
注意: 由于Cgroup namespace在4.6的内核中才实现,并且和cgroup v2关系密切,现在普及程度还不高,比如docker现在就还没有用它,所以在namespace这个系列中不会介绍Cgroup namespace。
当一个namespace中的所有进程都退出时,该namespace将会被销毁。当然还有其他方法让namespace一直存在,假设我们有一个进程号为1000的进程,以ipc namespace为例:
- 通过mount --bind命令。例如mount --bind /proc/1000/ns/ipc /other/file,就算属于这个ipc namespace的所有进程都退出了,只要/other/file还在,这个ipc namespace就一直存在,其他进程就可以利用/other/file,通过setns函数加入到这个namespace
- 在其他namespace的进程中打开/proc/1000/ns/ipc文件,并一直持有这个文件描述符不关闭,以后就可以用setns函数加入这个namespace。
UTS
UTS Namespace 用来隔离系统的主机名、hostname 和 NIS 域名。
- UTS namespace就是进程的一个属性,属性值相同的一组进程就属于同一个namespace,跟这组进程之间有没有亲戚关系无关
- clone和unshare都有创建并加入新的namespace的功能,他们的主要区别是:
- unshare是使当前进程加入新创建的namespace
- clone是创建一个新的子进程,然后让子进程加入新的namespace
- UTS namespace没有嵌套关系,即不存在说一个namespace是另一个namespace的父namespace
IPC
IPC 就是在不同进程间传递和交换信息。IPC Namespace 使得容器内的所有进程,进行的数据传输、共享数据、通知、资源共享等范围控制在所属容器内部,对宿主机和其他容器没有干扰。
mount
Mount Namespace 用来隔离文件系统的挂载点,不同的 Mount namespace 拥有各自独立的挂载点信息。在 Docker 这样的容器引擎中,Mount namespace 的作用就是保证容器中看到的文件系统的视图。
PID
PID namespaces用来隔离进程的 ID 空间,使得不同容器里的进程 ID 可以重复,相互不影响。
PID namespace可以嵌套,也就是说有父子关系,在当前namespace里面创建的所有新的namespace都是当前namespace的子namespace。父namespace里面可以看到所有子孙后代namespace里的进程信息,而子namespace里看不到祖先或者兄弟namespace里的进程信息。
network
network namespace用来隔离网络设备, IP地址, 端口等. 每个namespace将会有自己独立的网络栈,路由表,防火墙规则,socket等。
每个新的network namespace默认有一个本地环回接口,除了lo接口外,所有的其他网络设备(物理/虚拟网络接口,网桥等)只能属于一个network namespace。每个socket也只能属于一个network namespace。
当新的network namespace被创建时,lo接口默认是关闭的,需要自己手动启动起
标记为"local devices"的设备不能从一个namespace移动到另一个namespace,比如loopback, bridge, ppp等,我们可以通过ethtool -k命令来查看设备的netns-local属性。
user
User namespace用来隔离user权限相关的Linux资源,包括user IDs and group IDs,keys , 和capabilities.
cgroup简介
cgroup和namespace类似,也是将进程进行分组,但它的目的和namespace不一样,namespace是为了隔离进程组之间的资源,而cgroup是为了对一组进程进行统一的资源监控和限制。
cgroup分v1和v2两个版本,v1实现较早,功能比较多,但是由于它里面的功能都是零零散散的实现的,所以规划的不是很好,导致了一些使用和维护上的不便,v2的出现就是为了解决v1中这方面的问题,在最新的4.5内核中,cgroup v2声称已经可以用于生产环境了,但它所支持的功能还很有限,随着v2一起引入内核的还有cgroup namespace。v1和v2可以混合使用,但是这样会更复杂,所以一般没人会这样用。
用于:
- 将线程分组
- 对每组线程使用的多种物理资源进行限制和监控
cgroup
cgroup 有以下几个关键概念:
- 任务(Task):系统中的一个进程、线程。
- 在 cgroup v2 当中,进/线程与cgroup的关系如下:
- 所有 cgroup 组成一个树形结构(tree structure),
- 系统中的每个进程都属于且只属于某一个 cgroup;
- 一个进程的所有线程属于同一个 cgroup;
- 创建子进程时,继承其父进程的 cgroup;
- 一个进程可以被迁移到其他 cgroup;
- 迁移一个进程时,子进程(后代进程)不会自动跟着一起迁移;
- 控制组(Control Group):Cgroups进行资源监控和限制的基本单位,可以监控一个或多个task。控制组是有树状结构关系的,子控制组会继承父控制组的属性(资源配额,限制等)。控制组 指明了资源的配额限制,一个进程可以加入到某个控制组,也可以迁移到另一个控制组中.
- 子系统(Sub-system):可以跟踪或限制控制组使用该类型物理资源的内核组件。也叫资源控制器(Controller)。
- 控制器的所有行为都是具有层级传递性的,如果一个 cgroup 启用了某个控制器,那这个 cgroup 的 sub-hierarchy 中所有进程都会受控制。
- 层级(Hierarchy):由控制组组成的树状结构。通过被挂载到文件系统中形成。
mount | grep "type cgroup"可以查看。层级是作为控制组的根目录,来绑定controller,来达到对资源的控制。
注意:
- 每个层级需要绑定 controller 来进行资源控制
- 系统中可以存在多个层级,整个 Cgroups 的结构应该是多个树状结构
- 子控制组分配的资源不能超过父控制组分配的资源
相互之间的关系:
- 同一个层级可以附加绑定一个或多个
controller controller是可以同时附加到多个hierarchy,但是一个已经附加到某个层级的controller不能附加到其他含有其他controller的层级上,也就是说绑定多个层级后,这些层级都是只有唯一controller。- 一个任务不能存在于同一个层级的不同控制组,但是一个任务可以存在于不同层级中的多个控制组中
- 系统每创建一个层级时,该系统上的所有任务都会默认加入到这个层级的根控制组
- fork 或 clone 一个子任务时,会自动加入到父任务的控制组中,允许子任务移动到其他控制组, 没有限制
注意(v1版本):
- 一个Task在每个Hierarchy中只能属于一个Control Group
- 一个Sub-System只能附加于一个Hierarchy
- 一个Hierarchy可以附加于多个Sub-System
资源控制模型

Version1 to Version2
在Linux 2.6.24当中首次发行了 cgroups 的实现,各种 cgroup controller 之间的不协调导致了 cgroup hierarchy 管理变得非常复杂。
由于Version 1当中的问题,Linux 3.10开始设计一个全新的的cgroups实现来解决问题,最终在Linux 4.5版本中官方发行,即Version 2。
Cgroups v2 希望完全取代 Cgroups v1, 但是为了兼容,v1 并没有被移除,而且很多场景下都会作为系统的默认设置,当前的系统中可以同时使用 Cgroups v2 和 v1,但是一个 controller 只能选择一个版本使用。
v1 - v2 切换
在当前,系统中默认使用的是 cgroup v1。
重新启动内核时,添加一个参数systemd.unified_cgroup_hierarchy=1, 如:
grubby --update-kernel=ALL --args=systemd.unified_cgroup_hierarchy=1
与 v1 不同,cgroup v2 只有单个层级树(single hierarchy)。 用如下命令挂载 v2 hierarchy:
# mount -t <fstype> <device> <dir>
$ mount -t cgroup2 none $MOUNT_POINT
cgroupv2 文件系统 的 magic number 是 0x63677270 (“cgrp”)。
兼容性:
- 所有支持 v2 且未绑定到 v1 的控制器,会被自动绑定到 v2 hierarchy,出现在 root 层级中。
- v2 中未在使用的控制器(not in active use),可以绑定到其他 hierarchies。
这说明我们能以完全后向兼容的方式,混用 v2 和 v1 hierarchy。
Version 1
介绍
Controller即Cgroups的资源控制器,用于独立控制一种资源。
| 控制器 | 用途 |
|---|---|
| blkio | 限制cgroups中task的块设备io |
| cpu | 限制控制组下所有任务对 CPU 的使用 |
| cpuacct | 自动生成控制组中任务对 CPU 资源使用情况的报告 |
| cpuset | 为控制组中任务分配独立 CPU(针对多处理器系统) 和内存 |
| devices | 控制任务对设备的访问 |
| freezer | 挂起或恢复 控制组 中的任务 |
| memory | 限制控制组的内存使用量,自动生成任务对内存的使用情况报告 |
| pids | 限制控制组中进程可以派生出的进程数量 |
| net_cls | 通过使用等级识别符(classid)标记网络数据包,从而允许 Linux 流量控制程序(Traffic Controller, TC) 识别从具体 cgroup 中生成的数据包 |
| net_prio | 限制任务中网络流量的优先级 |
| perf_event | 可以对控制组中的任务进行统一的性能测试 |
| huge_tlb | 限制对 Huge page 的使用 |
| rdma | 限制 RDMA/IB 资源 |
Version 2
Version 2 的新变化:
Cgroups v2提供a unified hierarchy against which all controllers are mountedno Internal process,除了root cgroup之外,process 只能存在于leaf node(即 不能包含child cgroups的cgroups)之中。- 通过
cgroup.controllers和cgroup.subtree_control来指定Active cgroups - 移除
tasks文件。cpusetcontroller使用的cgroup.clone_chiledren被移除。 cgroup.events提供对于empty cgroup的增强版提醒机制
cgroup V2当中支持的Controller:
- cpu
- cpuset
- freezer
- hugetlb
- io
- memory
- perf_event
- pids
- rdma
联合文件系统
1、什么是UnionFS
联合文件系统(Union File System):2004年由纽约州立大学石溪分校开发,它可以把多个目录(也叫分支)内容联合挂载到同一个目录下,而目录的物理位置是分开的。UnionFS允许只读和可读写目录并存,就是说可同时删除和增加内容。UnionFS应用的地方很多,比如在多个磁盘分区上合并不同文件系统的主目录,或把几张CD光盘合并成一个统一的光盘目录(归档)。另外,具有写时复制(copy-on-write)功能UnionFS可以把只读和可读写文件系统合并在一起,虚拟上允许只读文件系统的修改可以保存到可写文件系统当中。
写时复制:copy-on-write,简写为 CoW,也叫隐式共享,是一种提高资源使用效率的资源管理技术。它的思想是:如果一个资源是重复的,在没有对资源做出修改前,并不需要立即复制出一个新的资源实例,这个资源被不同的所有者共享使用。当任何一个所有者要对该资源做出修改时,复制出一个新的资源实例给该所有者进行修改,修改后的资源成为其所有者的私有资源。通过这种资源共享的方式,可以显著地减少复制相同资源带来的消耗,但是这样做也会在进行资源的修改时增加一部分开销。
2、docker的镜像rootfs,和layer的设计
任何程序运行时都会有依赖,无论是开发语言层的依赖库,还是各种系统lib、操作系统等,不同的系统上这些库可能是不一样的,或者有缺失的。为了让容器运行时一致,docker将依赖的操作系统、各种lib依赖整合打包在一起(即镜像),然后容器启动时,作为它的根目录(根文件系统rootfs),使得容器进程的各种依赖调用都在这个根目录里,这样就做到了环境的一致性。
Docker镜像的设计中,引入了层(layer)的概念,也就是说,用户制作镜像的每一步操作,都会生成一个层,也就是一个增量rootfs(一个目录),这样应用A和应用B所在的容器共同引用相同的Debian操作系统层、Golang环境层(作为只读层),而各自有各自应用程序层,和可写层。启动容器的时候通过UnionFS把相关的层挂载到一个目录,作为容器的根文件系统。
需要注意的是,rootfs只是一个操作系统所包含的文件、配置和目录,并不包括操作系统内核。这就意味着,如果你的应用程序需要配置内核参数、加载额外的内核模块,以及跟内核进行直接的交互,你就需要注意了:这些操作和依赖的对象,都是宿主机操作系统的内核,它对于该机器上的所有容器来说是一个“全局变量”,牵一发而动全身。