
情景设计题.md 30 KB
了解分布式事务吗?
分布式系统中一次操作由多个服务协同完成,这种一次事务操作涉及多个系统通过网络协同完成的过程称为分布式事务。
分布式事务一般满足CAP原则
CAP 是 Consistency、Availability、Partition tolerance 三个单词的缩写,分别表示一致性、可用性、分区容忍性。
- 一个分布式系统最多同时满足一致性、可用性、分区容错性三项中的两项。
- 一般来讲都会选择保证A和P,舍弃一致性,保证最终一致性。
BASE理论
BASE是Basically Available(基本可用)、Soft state(软状态)和Eventually consistent(最终一致性)的缩写。
在分布式系统中,CAP理论是指导思维,而BASE理论是CAP理论中AP的延伸,是对 CAP 中的一致性和可用性进行一个权衡的结果,核心思想是:即使无法做到强一致性,但每个应用都可以根据自身的业务特点,采用适当的方式来使系统达到最终一致性。
- 基本可用(Basically Available):指分布式系统在出现故障的时候,允许损失部分可用性,保证核心可用。
- 柔性状态(Soft state):指允许系统存在中间状态,并认为该中间状态不会影响系统整体可用性。比如,允许不同节点间副本同步的延时就是柔性状态的体现。
- 最终一致性(Eventually consistent):指系统中的所有副本经过一定时间后,最终能够达到一致的状态。因此,最终一致性的本质是需要系统保证最终数据能够达到一致,而不需要实时保证系统数据的强一致性。
1、2PC/XA方案
所谓的 XA 方案,即:两阶段提交,有一个事务管理器的概念,负责协调多个数据库(资源管理器)的事务,事务管理器先问问各个数据库你准备好了吗?如果每个数据库都回复 ok,那么就正式提交事务,在各个数据库上执行操作;如果任何其中一个数据库回答不 ok,那么就回滚事务。
这种分布式事务方案,比较适合单块应用里,跨多个库的分布式事务,而且因为严重依赖于数据库层面来搞定复杂的事务,效率很低,绝对不适合高并发的场景。
一般来说某个系统内部如果出现跨多个库的这么一个操作,是不合规的。如果你要操作别人的服务的库,你必须是通过调用别的服务的接口来实现,绝对不允许交叉访问别人的数据库。
2、TCC强一致性方案
TCC 的全称是:Try、Confirm、Cancel。
- Try 阶段:这个阶段说的是对各个服务的资源做检测以及对资源进行 锁定或者预留。
- Confirm 阶段:这个阶段说的是在各个服务中执行实际的操作。
- Cancel 阶段:如果任何一个服务的业务方法执行出错,那么这里就需要 进行补偿,就是执行已经执行成功的业务逻辑的回滚操作。(把那些执行成功的回滚)
这种方案说实话几乎很少人使用,但是也有使用的场景。因为这个事务回滚实际上是严重依赖于你自己写逻辑来实现回滚和补偿,会造成巨大的补偿代码量。
3、可靠消息最终一致性方案
或者基于本地消息表
实现流程:
- 事务发起方发送Half事务消息
- RocketMq回复Half发送成功
- 事务发起方执行本地事务
- 事务发起方执行本地事务成功,发送commit到RocketMq,mq投递消息到事务参与方; 事务发起方执行本地事务失败,发送rollback到RocketMq,mq删除消息。
- 当RocketMq一定时间内未收到来自事务发起方的确认信息,会对事务发起方进行事务回查。
- 事务发起方查询本地事务状态。
- 事务发起方根据查询到的事务状态发送commint/rollback到RocketMq,继续走8或9。
- 当RocketMq发起commit后,收到失败或一定时间未收到成功ack,则会发起重试。
这个方案里,要是系统 B 的事务失败了咋办?重试咯,自动不断重试直到成功,如果实在是不行,要么就是针对重要的资金类业务进行回滚,比如 B 系统本地回滚后,想办法通知系统 A 也回滚;或者是发送报警由人工来手工回滚和补偿。
4、最大努力通知方案
- 系统 A 本地事务执行完之后,发送个消息到 MQ;
- 这里会有个专门消费 MQ 的最大努力通知服务,这个服务会消费 MQ 然后写入数据库中记录下来,或者是放入个内存队列也可以,接着调用系统 B 的接口;
- 要是系统 B 执行成功就 ok 了;要是系统 B 执行失败了,那么最大努力通知服务就定时尝试重新调用系统 B,反复 N 次,最后还是不行就放弃。
5、XA和TCC的区别
XA是把所有数据执行成功的通知发送给协调器(第一阶段),协调器在执行commit(第二阶段),并且数据源还要保证XA协议
TCC是第一阶段就把事务commit了(try接口),TCC的第二阶段是一个确认(Confirm)的阶段,也就是说只需要调用各个子系统里的confirm逻辑,所以在执行confirm逻辑的时候,并不会持有数据库的锁,所以不会产生性能问题。
如何设计一个高可用,高性能的系统?

1 无锁化
大多数情况下,多线程处理可以提高并发性能,但如果对共享资源的处理不当,严重的锁竞争也会导致性能的下降。面对这种情况,有些场景采用了无锁化设计,特别是在底层框架上。无锁化主要有两种实现,串行无锁和数据结构无锁。
1.1 串行无锁
无锁串行最简单的实现方式可能就是单线程模型了,如 redis/Nginx 都采用了这种方式。在网络编程模型中,常规的方式是主线程负责处理 I/O 事件,并将读到的数据压入队列,工作线程则从队列中取出数据进行处理,这种半同步/半异步模型需要对队列进行加锁,如下图所示:

上图的模式可以改成无锁串行的形式,当 MainReactor accept 一个新连接之后从众多的 SubReactor 选取一个进行注册,通过创建一个 Channel 与 I/O 线程进行绑定,此后该连接的读写都在同一个线程执行,无需进行同步。

1.2 结构无锁
利用硬件支持的原子操作可以实现无锁的数据结构,很多语言都提供 CAS 原子操作(如 go 中的 atomic 包和 C++11 中的 atomic 库),可以用于实现无锁队列。
2 零拷贝
3 序列化
当将数据写入文件、发送到网络、写入到存储时通常需要序列化(serialization)技术,从其读取时需要进行反序列化(deserialization),又称编码(encode)和解码(decode)。序列化作为传输数据的表示形式,与网络框架和通信协议是解耦的。如网络框架 taf 支持 jce、json 和自定义序列化,HTTP 协议支持 XML、JSON 和流媒体传输等。
序列化的方式很多,作为数据传输和存储的基础,如何选择合适的序列化方式尤其重要。
4 池子化
池化恐怕是最常用的一种技术了,其本质就是通过创建池子来提高对象复用,减少重复创建、销毁的开销。常用的池化技术有内存池、线程池、连接池、对象池等。
5 并发化
5.1 请求并发
如果一个任务需要处理多个子任务,可以将没有依赖关系的子任务并发化,这种场景在后台开发很常见。如一个请求需要查询 3 个数据,分别耗时 T1、T2、T3,如果串行调用总耗时 T=T1+T2+T3。对三个任务执行并发,总耗时 T=max(T1,T 2,T3)。同理,写操作也如此。对于同种请求,还可以同时进行批量合并,减少 RPC 调用次数。
5.2 冗余请求
冗余请求指的是同时向后端服务发送多个同样的请求,谁响应快就是使用谁,其他的则丢弃。这种策略缩短了客户端的等待时间,但也使整个系统调用量猛增,一般适用于初始化或者请求少的场景。公司 WNS 的跑马模块其实就是这种机制,跑马模块为了快速建立长连接同时向后台多个 ip/port 发起请求,谁快就用谁,这在弱网的移动设备上特别有用,如果使用等待超时再重试的机制,无疑将大大增加用户的等待时间。
6 异步化
对于处理耗时的任务,如果采用同步等待的方式,会严重降低系统的吞吐量,可以通过异步化进行解决。异步在不同层面概念是有一些差异的,在这里我们不讨论异步 I/O。
6.1 调用异步化
在进行一个耗时的 RPC 调用或者任务处理时,常用的异步化方式如下:
Callback:异步回调通过注册一个回调函数,然后发起异步任务,当任务执行完毕时会回调用户注册的回调函数,从而减少调用端等待时间。这种方式会造成代码分散难以维护,定位问题也相对困难。
Future:当用户提交一个任务时会立刻先返回一个 Future,然后任务异步执行,后续可以通过 Future 获取执行结果。对 1.4.1 中请求并发,我们可以使用 Future 实现,伪代码如下:
//异步并发任务
Future<Response> f1 = Executor.submit(query1);
Future<Response> f2 = Executor.submit(query2);
Future<Response> f3 = Executor.submit(query3);
//处理其他事情
doSomething();
//获取结果
Response res1 = f1.getResult();
Response res2 = f2.getResult();
Response res3 = f3.getResult();
- CPS
(Continuation-passing style)可以对多个异步编程进行编排,组成更复杂的异步处理,并以同步的代码调用形式实现异步效果。CPS 将后续的处理逻辑当作参数传递给 Then 并可以最终捕获异常,解决了异步回调代码散乱和异常跟踪难的问题。Java 中的 CompletableFuture 和 C++ PPL 基本支持这一特性。典型的调用形式如下:
void handleRequest(const Request &req)
{
return req.Read().Then([](Buffer &inbuf){
return handleData(inbuf);
}).Then([](Buffer &outbuf){
return handleWrite(outbuf);
}).Finally(){
return cleanUp();
});
}
6.2 流程异步化
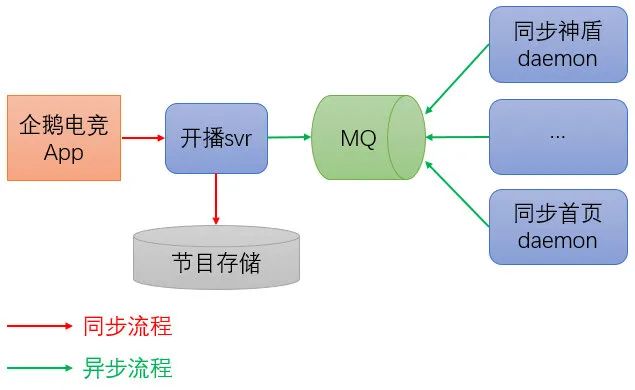
一个业务流程往往伴随着调用链路长、后置依赖多等特点,这会同时降低系统的可用性和并发处理能力。可以采用对非关键依赖进行异步化解决。如企鹅电竞开播服务,除了开播写节目存储以外,还需要将节目信息同步到神盾推荐平台、App 首页和二级页等。由于同步到外部都不是开播的关键逻辑且对一致性要求不是很高,可以对这些后置的同步操作进行异步化,写完存储即向 App 返回响应,如下图所示:
7 缓存
从单核 CPU 到分布式系统,从前端到后台,缓存无处不在。古有朱元璋“缓称王”而终得天下,今有不论是芯片制造商还是互联网公司都同样采取了“缓称王”(缓存称王)的政策才能占据一席之地。缓存是原始数据的一个复制集,其本质就是空间换时间,主要是为了解决高并发读。
- 进程级缓存:缓存的数据直接在进程地址空间内,这可能是访问速度最快使用最简单的缓存方式了。主要缺点是受制于进程空间大小,能缓存的数据量有限,进程重启缓存数据会丢失。一般通常用于缓存数据量不大的场景。
- 集中式缓存:缓存的数据集中在一台机器上,如共享内存。这类缓存容量主要受制于机器内存大小,而且进程重启后数据不丢失。常用的集中式缓存中间件有单机版 redis、memcache 等。
- 分布式缓存:缓存的数据分布在多台机器上,通常需要采用特定算法(如 Hash)进行数据分片,将海量的缓存数据均匀的分布在每个机器节点上。常用的组件有:Memcache(客户端分片)、Codis(代理分片)、Redis Cluster(集群分片)。
- 多级缓存:指在系统中的不同层级的进行数据缓存,以提高访问效率和减少对后端存储的冲击。以下图的企鹅电竞的一个多级缓存应用,根据我们的现网统计,在第一级缓存的命中率就已经达 94%,穿透到 grocery 的请求量很小。
8 分片
分片即将一个较大的部分分成多个较小的部分,在这里我们分为数据分片和任务分片。对于数据分片,在本文将不同系统的拆分技术术语(如 region、shard、vnode、partition)等统称为分片。分片可以说是一箭三雕的技术,将一个大数据集分散在更多节点上,单点的读写负载随之也分散到了多个节点上,同时还提高了扩展性和可用性。
数据分片,小到编程语言标准库里的集合,大到分布式中间件,无所不在。如我曾经写过一个线程安全的容器以放置各种对象时,为了减少锁争用,对容器进行了分段,每个分段一个锁,按照哈希或者取模将对象放置到某个分段中,如 Java 中的 ConcurrentHashMap 也采取了分段的机制。分布式消息中间件 Kafka 中对 topic 也分成了多个 partition,每个 partition 互相独立可以比并发读写。
- 一致性哈希
- 分库分表
- 任务分片,例如Map/Reduce
- 动态平衡,例如kafka的rebalance
9 存储
任何一个系统,从单核 CPU 到分布式,从前端到后台,要实现各式各样的功能和逻辑,只有读和写两种操作。而每个系统的业务特性可能都不一样,有的侧重读、有的侧重写,有的两者兼备,本节主要探讨在不同业务场景下存储读写的一些方法论。
9.1 读写分离
9.2 动静分离
9.3 冷热分离
9.4 重写轻读
10 队列
在系统应用中,不是所有的任务和请求必须实时处理,很多时候数据也不需要强一致性而只需保持最终一致性,有时候我们也不需要知道系统模块间的依赖,在这些场景下队列技术大有可为。
如何优化一个慢SQL?
在慢SQL的优化过程中,可以从以下五个角度去进行思考优化:SQL优化、资源占用、业务改造、数据减少、源头替换。
1. sql优化
SQL语句的优化方式主要是通过选择合适的索引、优化查询语句、避免全表扫描等提高查询效率,减少慢SQL的出现
- join优化,小表驱动大表,大表加索引
- in & exists
in执行流程:查询子查询的表且内外表有关联时,先执行内层表的子查询,然后将内表和外表做一个笛卡尔积,然后按照条件进行筛选,得到结果集。所以相对内表比较小的时候,in的速度较快
exists执行流程:指定一个子查询,检测行的存在。遍历循环外表,然后看外表中的记录有没有和内表的数据一样的,匹配上就将结果放入结果集中
- 建议使用not exists代替not in,not in使用的是全表扫描没有用到索引;而not exists在子查询依然能用到表上的索引
- 使用索引
2. 资源占用
- 锁资源等待:在读写很热的表上,通常会发生锁资源争夺,从而导致慢查询的情况
- 谨慎使用for update
- 增删改尽量使用到索引
- 降低并发,避免对同一条数据进行反复修改
- 网络波动:往客户端发送数据时发生网络波动导致的慢查询
- 硬件配置:CPU利用率高,磁盘IO经常满载,导致慢查询
在高并发、高流量下,数据库所在机器的负载load过高也会导致SQL整体执行时间过长,这时可能需要从机器和实例的分配,分布式部署,分库分表,读写分离等角度进行优化
3. 业务改造
- 是不是真的需要全部查出来,还是取其中的top N就能够满足需求了
- 查询条件过多的情况下,能否前端页面提示限制过多的查询条件的使用
- 针对实时导出的数据,涉及到实时查DB导出大量数据时,限制导出数据量 or 走T+1的离线导出是不是也是可以的
- 现在业务上需要做数据搜索,使用了 LIKE “%关键词%” 做全模糊查询,从而导致了慢SQL。是不是可以让业务方妥协下,最右模糊匹配,这样就可以利用上索引了
4. 源头替换
Mysql并不是任何的查询场景都是适合的,如需要支持全模糊搜索时,全模糊的like是无法走到索引的。同时结合数据本身的生命周期,对于热点数据,可以考虑存储到缓存解决。因此针对不适合mysql数据源的情况,我们需要替代新的存储介质
- 有like的全模糊的查询,比如基于文本内容去查订单信息,需要接搜索引擎解决
- 有热点数据的查询,考虑是否要接缓存解决
- 针对复杂条件的海量数据查询,可以考虑切换到OLAP(Online Analytical Processing),可以考虑接Hybrid DB或ADB通道
- 有些场景Mysql不适用,需要用K-V的数据库,HBASE等列式存储的存储引擎
5. 数据减少
QL本身的性能已经到达极限了,但是耗时仍然很长,可能由于数据量或索引数据都比较大了。因此需要从数据量级减少的角度去处理
- 使用分库分表。由于单表的数据量过大,例如达到千万级别的数据了,需要使用分库分表技术拆分后减轻单库单表的单点压力
- 定时清理终态数据。针对已经状态为终态的业务单据或明显信息,可以使用idb历史数据清理的方式配置定时自动清理。如针对我们的仓储库存操作明细为完结状态的数据,我们只保留最近1天的数据在db中,其他直接删除,减少db查询压力
- 统计类查询可以单独维护汇总数据表。参考数据仓库中的数据分层设计,基于明细数据,抽出一张指标汇总表,或7天/15天等的视图数据进行预计算。此类汇总表数据量级相比明细表下降很多,从而避免直接根据大量明细查询聚合造成慢sql
如何设计B站?
- 用户推荐方向:可以从视频分类,然后按照用户标签去分析。
- 缓存,可以用本地缓存,类似map/reduce批量去更新
什么是负载均衡
第 1 层:客户端层 -> 反向代理层 的负载均衡。通过 DNS 轮询
第 2 层:反向代理层 -> Web 层 的负载均衡。通过 Nginx 的负载均衡模块
第 3 层:Web 层 -> 业务服务层 的负载均衡。通过服务治理框架的负载均衡模块
第 4 层:业务服务层 -> 数据存储层 的负载均衡。通过数据的水平分布,数据均匀了,理论上请求也会均匀。比如通过买家ID分片类似
限流算法介绍
限制到达系统的并发请求数,使得系统能够正常的处理 部分 用户的请求,来保证系统的稳定性。
计数器法
最简单粗暴的一种算法,比如说一个接口一分钟内的请求不能超过60次
- 划分时间窗口
- 窗口内请求,计数器加一
- 超过限制,本窗口内拒绝请求,等到下个窗口,计数器重置,再执行请求
应用场景:短信限流,比如一个用户一分钟内一条短信,可以使用计数器限流
问题:临界问题,两个时间窗口交界处,可能会执行任务,近似于通知执行两倍量的任务
滑动窗口算法
在固定窗口划分多个小窗口,分别在小时间窗口里记录访问次数,随着时间推动窗口滑动并删除过期窗口,即去除之前的访问次数,最终统计所有小窗口的可访问总数。
demo:将1min分为4个小窗口,每个小窗口能处理25个请求。通过虚线表示窗口大小(当前窗口大小为2,所以能处理50个请求)。同时窗口可以随时间滑动,比如15s后,窗口滑动到(15s-45s)这个范围内,然后在新的窗口里进行统计
当滑动窗口的小时间窗口划分越多,那么滑动窗口的滑动就越平滑,限流的统计就更精确。
漏桶算法
内部维护一个容器,以恒定的速度出水,不管上游的速度多快。请求到达时直接放入到漏桶中,如果容量达到上限(阈值),则进行丢弃(执行限流策略)。
漏桶算法无法短时间处理突发流量,是一种恒定的限流算法。
令牌算法(rateLimter)
令牌桶是网络流量整形(Traffic Shaping)和速度限制(Rate Limting)中最常使用的算法,对于每个请求,都需要从令牌桶中获得一个令牌,如果没有令牌则触发限流策略。
系统以一个恒定的速度往固定容量的容器放入令牌,如果有请求,则需要从令牌桶中取出令牌才能放行。
由于令牌桶有固定大小,当请求速度<生成令牌速度,令牌桶会被填满,因此令牌桶可以处理突发流量。
linux的tail
- 命令行解析: 使用 Python 的
argparse模块来解析命令行参数,包括文件路径、行数、是否实时监视等选项。 - 打开文件: 使用 Python 的
open函数打开用户指定的文件。我会使用with语句来确保在使用完文件后正确关闭它。 - 定位到末尾: 使用
file.seek()方法将文件指针定位到文件末尾。这样,我就可以从末尾开始逐行读取。 - 逐行读取和输出: 使用循环,我会从文件末尾逐行读取内容,并将这些内容打印到终端。我会维护一个计数器,确保只输出指定数量的行。
- 实时监视: 如果需要支持实时监视,我会使用一个循环来不断检查文件是否有新内容添加。我可以使用
time.sleep()等方法来实现定期检查,并在发现新行时输出到终端。 - 错误处理: 我会考虑处理可能出现的错误,例如文件不存在、无法打开文件等情况。在出现错误时,我会向用户提供友好的错误消息。
- 边界情况: 我会确保处理一些边界情况,例如用户提供的行数大于文件总行数的情况
如果是大文件直接读取inode文件内容
定位到末尾的块: 文件的 inode 包含了文件数据块的指针。你可以首先通过 inode 获取文件的大小,然后确定需要读取的块数量。这可以帮助你跳过文件的开头部分。
负载均衡策略
- 轮询
- 加权轮询
- 哈希算法
- IP哈希
- URL哈希
- 一致性哈希
- 最小响应时间
- 随机
- 粘性
降级和熔断
基本的容错模式
常见的容错模式主要包含以下几种方式
- 主动超时:Http请求主动设置一个超时时间,超时就直接返回,不会造成服务堆积
- 限流:限制最大并发数
- 熔断:当错误数超过阈值时快速失败,不调用后端服务,同时隔一定时间放几个请求去重试后端服务是否能正常调用,如果成功则关闭熔断状态,失败则继续快速失败,直接返回。(此处有个重试,重试就是弹性恢复的能力)
- 隔离:把每个依赖或调用的服务都隔离开来,防止级联失败引起整体服务不可用
- 降级:服务失败或异常后,返回指定的默认信息

服务降级
由于爆炸性的流量冲击,对一些服务进行有策略的放弃,以此缓解系统压力,保证目前主要业务的正常运行。它主要是针对非正常情况下的应急服务措施:当此时一些业务服务无法执行时,给出一个统一的返回结果。
降级服务的特征
- 原因:整体负荷超出整体负载承受能力。
- 目的:保证重要或基本服务正常运行,非重要服务延迟使用或暂停使用
- 大小:降低服务粒度,要考虑整体模块粒度的大小,将粒度控制在合适的范围内
- 可控性:在服务粒度大小的基础上增加服务的可控性,后台服务开关的功能是一项必要配置(单机可配置文件,其他可领用数据库和缓存),可分为手动控制和自动控制。
- 次序:一般从外围延伸服务开始降级,需要有一定的配置项,重要性低的优先降级,比如可以分组设置等级1-10,当服务需要降级到某一个级别时,进行相关配置
降级方式
- 延迟服务:比如发表了评论,重要服务,比如在文章中显示正常,但是延迟给用户增加积分,只是放到一个缓存中,等服务平稳之后再执行。
- 在粒度范围内关闭服务(片段降级或服务功能降级):比如关闭相关文章的推荐,直接关闭推荐区
- 页面异步请求降级:比如商品详情页上有推荐信息/配送至等异步加载的请求,如果这些信息响应慢或者后端服务有问题,可以进行降级;
- 页面跳转(页面降级):比如可以有相关文章推荐,但是更多的页面则直接跳转到某一个地址
- 写降级:比如秒杀抢购,我们可以只进行Cache的更新,然后异步同步扣减库存到DB,保证最终一致性即可,此时可以将DB降级为Cache。
- 读降级:比如多级缓存模式,如果后端服务有问题,可以降级为只读缓存,这种方式适用于对读一致性要求不高的场景。
降级预案
在进行降级之前要对系统进行梳理,看看系统是不是可以丢卒保帅;从而梳理出哪些必须誓死保护,哪些可降级;比如可以参考日志级别设置预案:
- 一般:比如有些服务偶尔因为网络抖动或者服务正在上线而超时,可以自动降级;
- 警告:有些服务在一段时间内成功率有波动(如在95~100%之间),可以自动降级或人工降级,并发送告警;
- 错误:比如可用率低于90%,或者数据库连接池被打爆了,或者访问量突然猛增到系统能承受的最大阀值,此时可以根据情况自动降级或者人工降级;
- 严重错误:比如因为特殊原因数据错误了,此时需要紧急人工降级。
服务降级分类
- 降级按照是否自动化可分为:自动开关降级(超时、失败次数、故障、限流)和人工开关降级(秒杀、电商大促等)。
- 降级按照功能可分为:读服务降级、写服务降级。
- 降级按照处于的系统层次可分为:多级降级。
自动降级分类
- 超时降级:主要配置好超时时间和超时重试次数和机制,并使用异步机制探测回复情况
- 失败次数降级:主要是一些不稳定的api,当失败调用次数达到一定阀值自动降级,同样要使用异步机制探测回复情况
- 故障降级:比如要调用的远程服务挂掉了(网络故障、DNS故障、http服务返回错误的状态码、rpc服务抛出异常),则可以直接降级。降级后的处理方案有:默认值(比如库存服务挂了,返回默认现货)、兜底数据(比如广告挂了,返回提前准备好的一些静态页面)、缓存(之前暂存的一些缓存数据)
- 限流降级: 当我们去秒杀或者抢购一些限购商品时,此时可能会因为访问量太大而导致系统崩溃,此时开发者会使用限流来进行限制访问量,当达到限流阀值,后续请求会被降级;降级后的处理方案可以是:排队页面(将用户导流到排队页面等一会重试)、无货(直接告知用户没货了)、错误页(如活动太火爆了,稍后重试)
服务降级需考虑的问题
- 核心服务或非核心服务。
- 是否支持降级,及其降级策略。
- 业务放通场景,极其策略。
服务熔断
在学习服务熔断时,有必要区分下如下几个相关的概念。
- 服务雪崩
多个微服务之间调用的时候,假设微服务A调用微服务B和微服务C,微服务B和微服务C有调用其他的微服务,如果整个链路上某个微服务的调用响应式过长或者不可用,对微服务A的调用就会占用越来越多的系统资源,进而引起系统雪崩,所谓的”雪崩效应”
- 断路器
“断路器”本身是一种开关装置,当某个服务单元发生故障监控(类似熔断保险丝),向调用方法返回一个符合预期的、可处理的备选响应(FallBack),而不是长时间的等待或者抛出调用方法无法处理的异常,这样就保证了服务调用方的线程不会被长时间、不必要地占用,从而避免了故障在分布式系统中的蔓延。乃至雪崩。
- 服务熔断
熔断机制是应对雪崩效应的一种微服务链路保护机制,当整个链路的某个微服务不可用或者响应时间太长时,会进行服务的降级,进而熔断该节点微服务的调用,快速返回”错误”的响应信息。
- Hystrix
Hystrix是一个用于分布式系统的延迟和容错的开源库。在分布式系统里,许多依赖不可避免的调用失败,比如超时、异常等,Hystrix能够保证在一个依赖出问题的情况下,不会导致整个服务失败,避免级联故障,以提高分布式系统的弹性。
熔断流程
- 基本的断路器模式

它有两个基本状态(close和open)和一个基本trip动作:
- close状态下, client向supplier发起的服务请求, 直接无阻碍通过断路器, supplier的返回值接直接由断路器交回给client.
- open状态下,client向supplier发起的服务请求后,断路器不会将请求转到supplier, 而是直接返回client, client和supplier之间的通路是断的
- trip: 在close状态下,如果supplier持续超时报错, 达到规定的阀值后,断路器就发生trip, 之后断路器状态就会从close进入open.
- 扩展的断路器模式
基本的断路器模式下,保证了断路器在open状态时,保护supplier不会被调用, 但我们还需要额外的措施可以在supplier恢复服务后,可以重置断路器。一种可行的办法是断路器定期探测supplier的服务是否恢复, 一但恢复, 就将状态设置成close。断路器进行重试时的状态为半开(half-open)状态。
