
集合.md 11 KB
hashmap
put方法
该方法首先会判断hashmap的数组是否被初始化,如果没有初始化,则首先进行初始化操作。其次判断该key是不是null,如果为null则在数组下标为0的地方进行插入操作,如果不为null,则进行下一步判断。 如果数组该位置为null,则新建一个node,进行插入,如果不为null,则采用头插法插入元素,如果链表长度大于8,并且数组长度大于64,则将链表转换为红黑树。如果小于64则直接扩容
为什么hashmap长度为16
- 减少hash冲突
- 每次扩容只用移动一半的元素
这是因为hashmap缓存了key的hash值,每次移动元素只需要新的高位与1相与就行。
get方法
判断该元素时候为空,如果为空直接返回,如果不为空则返回value
为什么选择红黑树
红黑树相比avl树,在检索的时候效率其实差不多,都是通过平衡来二分查找。但对于插入删除等操作效率提高很多。红黑树不像avl树一样追求绝对的平衡,他允许局部很少的不完全平衡,这样对于效率影响不大,但省去了很多没有必要的调平衡操作,avl树调平衡有时候代价较大,所以效率不如红黑树。
Java 中的 HashMap 底层原理使用数组和链表/红黑树实现,而不使用 B 树,原因有以下几点:
- 红黑树的查找、插入、删除操作复杂度相对稳定,不会像 B 树 那样随着树高逐渐变差,平均时间复杂度为 O(log n)。B 树虽然有更快的查找速度,但在 Java 中,HashMap 的数据量一般都在1K以下,单机内存完全可以满足红黑树的需求。
- 空间利用率方面,B 树中非叶子节点需要存储下一级节点的指针,因此每个节点占用的空间相对较大,而红黑树只需要保存左右子节点和父节点的指针,所以相对来说更加节省空间。
- 红黑树相对于 B 树 更容易实现。
- 在实际应用中,虽然B树比红黑树有更优异的性能表现,但其实现比较复杂,在使用时需要结合具体场景来考虑。相比之下,红黑树实现简单,维护成本低,且平均情况下的性能也能够满足HashMap的需求,因此选择红黑树作为HashMap的底层数据结构更为合适。
综上所述,HashMap 选择红黑树而不是 B 树 作为其底层数据结构,主要是出于对效率和实现的考虑。
红黑树特征:
- 每个节点或者是黑色,或者是红色。
- 根节点是黑色。
- 每个叶子节点(NIL)是黑色。
- 如果一个节点是红色的,则它的子节点必须是黑色的。
- 从一个节点到该节点的子孙节点的所有路径上包含相同数目的黑节点。
负载因子为什么是0.75
而加载因子就是表示Hash表中元素的填满程度。
加载因子 = 填入表中的元素个数 / 散列表的长度
加载因子越大,填满的元素越多,空间利用率越高,但发生冲突的机会变大了;
加载因子越小,填满的元素越少,冲突发生的机会减小,但空间浪费了更多了,而且还会提高扩容rehash操作的次数。
(泊松分布)选择0.75作为默认的加载因子,完全是时间和空间成本上寻求的一种折衷选择。
解决冲突的方法
1. 开放定址法
Hi = (H(key) + di) MOD m,其中i=1,2,…,k(k<=m-1)
H(key)为哈希函数,m为哈希表表长,di为增量序列,i为已发生冲突的次数。其中,开放定址法根据步长不同可以分为3种:
1.1 线性探查法(Linear Probing):di = 1,2,3,…,m-1
简单地说,就是以当前冲突位置为起点,步长为1循环查找,直到找到一个空的位置,如果循环完了都占不到位置,就说明容器已经满了。举个栗子,就像你在饭点去街上吃饭,挨家去看是否有位置一样。
1.2 平方探测法(Quadratic Probing):di = ±12, ±22,±32,…,±k2(k≤m/2)
相对于线性探查法,这就相当于的步长为di = i2来循环查找,直到找到空的位置。以上面那个例子来看,现在你不是挨家去看有没有位置了,而是拿手机算去第i2家店,然后去问这家店有没有位置。
1.3 伪随机探测法:di = 伪随机数序列
这个就是取随机数来作为步长。还是用上面的例子,这次就是完全按心情去选一家店问有没有位置了。
但开放定址法有这些缺点:
- 这种方法建立起来的哈希表,当冲突多的时候数据容易堆集在一起,这时候对查找不友好;
- 删除结点的时候不能简单将结点的空间置空,否则将截断在它填入散列表之后的同义词结点查找路径。因此如果要删除结点,只能在被删结点上添加删除标记,而不能真正删除结点;
- 如果哈希表的空间已经满了,还需要建立一个溢出表,来存入多出来的元素。
2. 再哈希法
Hi = RHi(key), 其中i=1,2,…,k
RHi()函数是不同于H()的哈希函数,用于同义词发生地址冲突时,计算出另一个哈希函数地址,直到不发生冲突位置。这种方法不容易产生堆集,但是会增加计算时间。
所以再哈希法的缺点是:增加了计算时间。
3. 链地址法(拉链法)
将冲突位置的元素构造成链表。在添加数据的时候,如果哈希地址与哈希表上的元素冲突,就放在这个位置的链表上。
拉链法的优点:
- 处理冲突的方式简单,且无堆集现象,非同义词绝不会发生冲突,因此平均查找长度较短;
- 由于拉链法中各链表上的结点空间是动态申请的,所以它更适合造表前无法确定表长的情况;
- 删除结点操作易于实现,只要简单地删除链表上的相应的结点即可。
拉链法的缺点:需要额外的存储空间。
从HashMap的底层结构中我们可以看到,HashMap采用是数组+链表/红黑树的组合来作为底层结构,也就是开放地址法+链地址法的方式来实现HashMap。
4. 建立公共溢出区:将哈希表分为基本表和溢出表,将发生冲突的都存放在溢出表中。
HashTable如何保证线程安全
HashMap是非同步的,没有对读写等操作进行锁保护,是线程不安全的。 Hashtable是同步的,所有的读写操作都进行了锁保护,是线程安全的。 Hashtable的底层是数组+链表实现的
简单一句话:加锁
ConcurrentHashMap1.7
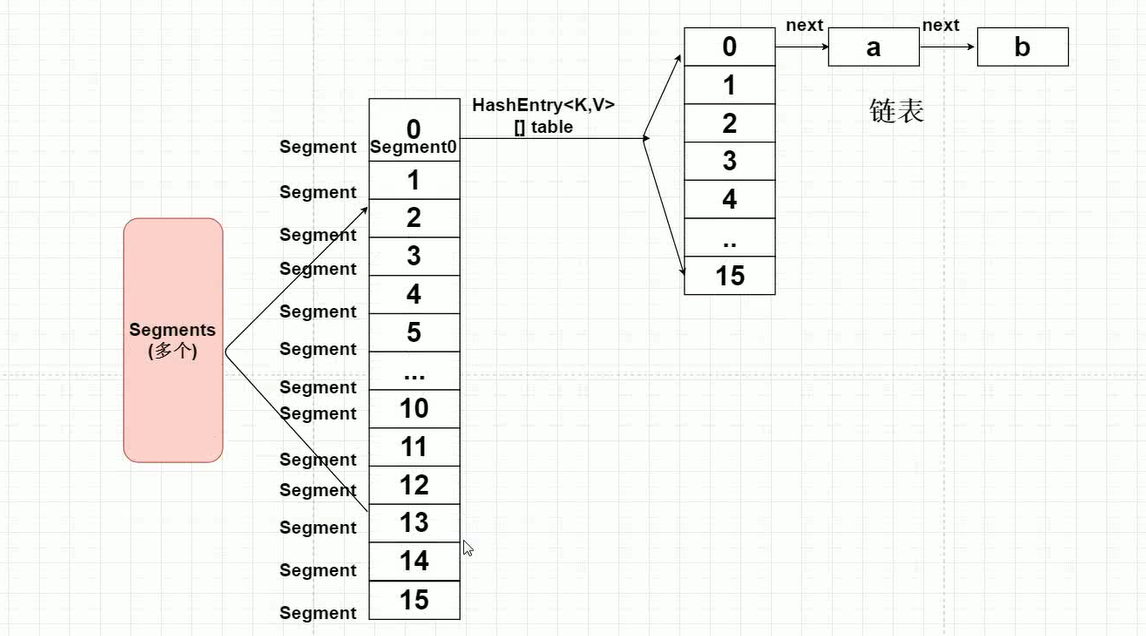
Java 7 中 ConcurrentHashMap 的存储结构如上图,ConcurrnetHashMap 由很多个 Segment 组合,而每一个 Segment 是一个类似于 HashMap 的结构,所以每一个 HashMap 的内部可以进行扩容。但是 Segment 的个数一旦初始化就不能改变,默认 Segment 的个数是 16 个,你也可以认为 ConcurrentHashMap 默认支持最多 16 个线程并发。
初始化逻辑
- 必要参数校验。
- 校验并发级别
concurrencyLevel大小,如果大于最大值,重置为最大值。无参构造默认值是 16. - 寻找并发级别
concurrencyLevel之上最近的 2 的幂次方值,作为初始化容量大小,默认是 16。 - 记录
segmentShift偏移量,这个值为【容量 = 2 的 N 次方】中的 N,在后面 Put 时计算位置时会用到。默认是 32 - sshift = 28. - 记录
segmentMask,默认是 ssize - 1 = 16 -1 = 15. - 初始化
segments[0],默认大小为 2,负载因子 0.75,扩容阀值是 2*0.75=1.5,插入第二个值时才会进行扩容。
为什么在构造函数初始化s0?
方便后期其他key落到不同的segment中,能够知道加载因子,和默认容量一些基本参数,就是相当于提供了一个模板
put方法逻辑
- 计算要 put 的 key 的位置,获取指定位置的
Segment。 如果指定位置的
Segment为空,则初始化这个Segment.初始化 Segment 流程:
- 检查计算得到的位置的
Segment是否为 null. - 为 null 继续初始化,使用
Segment[0]的容量和负载因子创建一个HashEntry数组。 - 再次检查计算得到的指定位置的
Segment是否为 null. - 使用创建的
HashEntry数组初始化这个 Segment. - 自旋判断计算得到的指定位置的
Segment是否为 null,使用 CAS 在这个位置赋值为Segment.
- 检查计算得到的位置的
Segment.put插入 key,value 值。
put方法低层逻辑
tryLock()获取锁,获取不到使用scanAndLockForPut方法继续获取。- 计算 put 的数据要放入的 index 位置,然后获取这个位置上的
HashEntry。 - 遍历 put 新元素,为什么要遍历?因为这里获取的
HashEntry可能是一个空元素,也可能是链表已存在,所以要区别对待。 如果这个位置上的
HashEntry不存在:- 如果当前容量大于扩容阀值,小于最大容量,进行扩容。
- 直接头插法插入。
如果这个位置上的
HashEntry存在:- 判断链表当前元素 key 和 hash 值是否和要 put 的 key 和 hash 值一致。一致则替换值
- 不一致,获取链表下一个节点,直到发现相同进行值替换,或者链表表里完毕没有相同的。
- 如果当前容量大于扩容阀值,小于最大容量,进行扩容。
- 直接链表头插法插入。
如果要插入的位置之前已经存在,替换后返回旧值,否则返回 null.
扩容
ConcurrentHashMap 的扩容只会扩容到原来的两倍。老数组里的数据移动到新的数组时,位置要么不变,要么变为 index+ oldSize,参数里的 node 会在扩容之后使用链表头插法插入到指定位置。
ConcurrentHashMap1.8
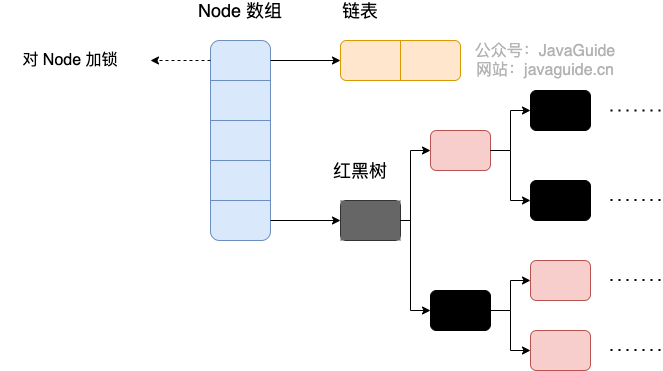
初始化逻辑
ConcurrentHashMap的初始化是通过自旋和 CAS 操作完成的
put方法
- 根据 key 计算出 hashcode 。
- 判断是否需要进行初始化。
- 即为当前 key 定位出的 Node,如果为空表示当前位置可以写入数据,利用 CAS 尝试写入,失败则自旋保证成功。
- 如果当前位置的
hashcode == MOVED == -1,则需要进行扩容。 - 如果都不满足,则利用 synchronized 锁写入数据。
- 如果数量大于
TREEIFY_THRESHOLD则要执行树化方法,在treeifyBin中会首先判断当前数组长度 ≥64 时才会将链表转换为红黑树。
cas使用时候:没有发生冲突的时候 synchronized使用:index发生冲突的时候
get方法
- 根据 hash 值计算位置。
- 查找到指定位置,如果头节点就是要找的,直接返回它的 value.
- 如果头节点 hash 值小于 0 ,说明正在扩容或者是红黑树,查找之。
- 如果是链表,遍历查找之。