|
|
@@ -189,3 +189,88 @@ TLB即为页表缓存、转址旁路缓存、快表等。有了 TLB 后,那么
|
|
|
1. **静态分配策略**:一个进程必须在执行前就申请到它所需要的全部资源
|
|
|
2. **层次分配策略**:一个进程得到某一次的一个资源后,它只能再申请较高一层的资源
|
|
|
|
|
|
+## 零拷贝
|
|
|
+
|
|
|
+**传统的拷贝**
|
|
|
+
|
|
|
+
|
|
|
+
|
|
|
+**一共需要2次CPU拷贝,很消耗时间。**
|
|
|
+
|
|
|
+
|
|
|
+
|
|
|
+零拷贝(Zero-Copy)是一种 `I/O` 操作优化技术,可以快速高效地将数据从文件系统移动到网络接口,而不需要将其从内核空间复制到用户空间。
|
|
|
+
|
|
|
+技术的核心就要是减少CPU占用和上下文切换
|
|
|
+
|
|
|
+它主要由以下4点技术结合实现:
|
|
|
+
|
|
|
+### 1. DMA技术
|
|
|
+
|
|
|
+DMA(Direct Memory Access)是一种硬件实现的技术,能够直接将数据从设备传输到内存中,而无需CPU参与其中。
|
|
|
+
|
|
|
+### 2. 缓冲区技术
|
|
|
+
|
|
|
+在实现零拷贝时,需要使用多个缓冲区来存储数据。通过缓冲区技术可以实现不同层级的内存之间的数据传输。
|
|
|
+
|
|
|
+### 3. 文件映射技术
|
|
|
+
|
|
|
+文件映射技术可以将文件或磁盘块映射到内存空间中,使得应用程序可以直接访问这些文件或磁盘块,从而实现零拷贝。
|
|
|
+
|
|
|
+**mmap + write**
|
|
|
+
|
|
|
+
|
|
|
+
|
|
|
+`mmap()` 系统调用函数会直接把内核缓冲区里的数据「**映射**」到用户空间,这样,操作系统内核与用户空间就不需要再进行任何的数据拷贝操作。
|
|
|
+
|
|
|
+具体过程如下:
|
|
|
+
|
|
|
+- 应用进程调用了 `mmap()` 后,DMA 会把磁盘的数据拷贝到内核的缓冲区里。接着,应用进程跟操作系统内核「共享」这个缓冲区;
|
|
|
+- 应用进程再调用 `write()`,操作系统直接将内核缓冲区的数据拷贝到 socket 缓冲区中,这一切都发生在内核态,由 CPU 来搬运数据;
|
|
|
+- 最后,把内核的 socket 缓冲区里的数据,拷贝到网卡的缓冲区里,这个过程是由 DMA 搬运的。
|
|
|
+
|
|
|
+但这还不是最理想的零拷贝,因为仍然需要通过 CPU 把内核缓冲区的数据拷贝到 socket 缓冲区里,而且仍然需要 4 次上下文切换,因为系统调用还是 2 次
|
|
|
+
|
|
|
+### 4. 网络协议技术
|
|
|
+
|
|
|
+网络协议技术可以帮助实现在网络上进行零拷贝传输,例如在TCP/IP协议栈中使用sendfile系统调用。
|
|
|
+
|
|
|
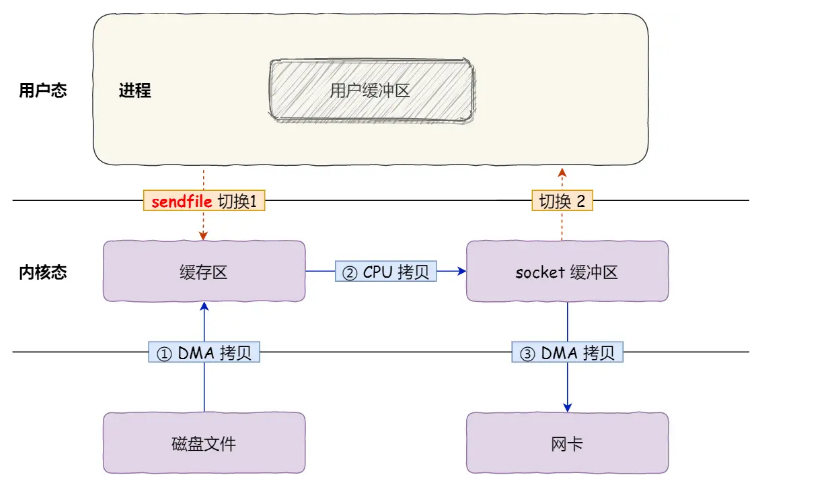
+**sendfile**
|
|
|
+
|
|
|
+
|
|
|
+
|
|
|
+- 第一步,通过 DMA 将磁盘上的数据拷贝到内核缓冲区里;
|
|
|
+- 第二步,缓冲区描述符和数据长度传到 socket 缓冲区,这样网卡的 SG-DMA 控制器就可以直接将内核缓存中的数据拷贝到网卡的缓冲区里,此过程不需要将数据从操作系统内核缓冲区拷贝到 socket 缓冲区中,这样就减少了一次数据拷贝;
|
|
|
+
|
|
|
+## PageCache 有什么作用?
|
|
|
+
|
|
|
+**零拷贝使用了 PageCache 技术**,***PageCache\***其实本质上就是一种**磁盘高速缓存**,通过 DMA 把磁盘里的数据搬运到内存里,这样就可以用读内存替换读磁盘。
|
|
|
+
|
|
|
+**PageCache 来缓存最近被访问的数据**,当空间不足时淘汰最久未被访问的缓存。所以,读磁盘数据的时候,优先在 PageCache 找,如果数据存在则可以直接返回;如果没有,则从磁盘中读取,然后缓存 PageCache 中。
|
|
|
+
|
|
|
+还有一点,读取磁盘数据的时候,需要找到数据所在的位置,但是对于机械磁盘来说,就是通过磁头旋转到数据所在的扇区,再开始「顺序」读取数据,但是旋转磁头这个物理动作是非常耗时的,为了降低它的影响,**PageCache 使用了「预读功能」**。
|
|
|
+
|
|
|
+比如,假设 read 方法每次只会读 `32 KB` 的字节,虽然 read 刚开始只会读 0 ~ 32 KB 的字节,但内核会把其后面的 32~64 KB 也读取到 PageCache,这样后面读取 32~64 KB 的成本就很低,如果在 32~64 KB 淘汰出 PageCache 前,进程读取到它了,收益就非常大。
|
|
|
+
|
|
|
+所以,PageCache 的优点主要是两个:
|
|
|
+
|
|
|
+- 缓存最近被访问的数据;
|
|
|
+- 预读功能;
|
|
|
+
|
|
|
+这两个做法,将大大提高读写磁盘的性能。
|
|
|
+
|
|
|
+## 大文件传输用什么方式实现?
|
|
|
+
|
|
|
+**在传输大文件(GB 级别的文件)的时候,PageCache 会不起作用,那就白白浪费 DMA 多做的一次数据拷贝,造成性能的降低,即使使用了 PageCache 的零拷贝也会损失性能**
|
|
|
+
|
|
|
+**在高并发的场景下,针对大文件的传输的方式,应该使用「异步 I/O + 直接 I/O」来替代零拷贝技术**。
|
|
|
+
|
|
|
+直接 I/O 应用场景常见的两种:
|
|
|
+
|
|
|
+- 应用程序已经实现了磁盘数据的缓存,那么可以不需要 PageCache 再次缓存,减少额外的性能损耗。在 MySQL 数据库中,可以通过参数设置开启直接 I/O,默认是不开启;
|
|
|
+- 传输大文件的时候,由于大文件难以命中 PageCache 缓存,而且会占满 PageCache 导致「热点」文件无法充分利用缓存,从而增大了性能开销,因此,这时应该使用直接 I/O。
|
|
|
+
|
|
|
+另外,由于直接 I/O 绕过了 PageCache,就无法享受内核的这两点的优化:
|
|
|
+
|
|
|
+- 内核的 I/O 调度算法会缓存尽可能多的 I/O 请求在 PageCache 中,最后「**合并**」成一个更大的 I/O 请求再发给磁盘,这样做是为了减少磁盘的寻址操作;
|
|
|
+- 内核也会「**预读**」后续的 I/O 请求放在 PageCache 中,一样是为了减少对磁盘的操作;
|

{kind=link}

{kind=link}
{kind=link}
