|
|
@@ -0,0 +1,230 @@
|
|
|
+## 了解分布式事务吗?
|
|
|
+
|
|
|
+分布式事务一般满足CAP原则
|
|
|
+
|
|
|
+CAP 是 Consistency、Availability、Partition tolerance 三个单词的缩写,分别表示一致性、可用性、分区容忍性。
|
|
|
+
|
|
|
+* 一个分布式系统最多同时满足一致性、可用性、分区容错性三项中的两项。
|
|
|
+
|
|
|
+* 一般来讲都会选择保证A和P,舍弃一致性,保证最终一致性。
|
|
|
+
|
|
|
+### 1、2PC/XA方案
|
|
|
+
|
|
|
+所谓的 XA 方案,即:两阶段提交,有一个事务管理器的概念,负责协调多个数据库(资源管理器)的事务,事务管理器先问问各个数据库你准备好了吗?如果每个数据库都回复 ok,那么就正式提交事务,在各个数据库上执行操作;如果任何其中一个数据库回答不 ok,那么就回滚事务。
|
|
|
+
|
|
|
+这种分布式事务方案,比较适合单块应用里,跨多个库的分布式事务,而且因为严重依赖于数据库层面来搞定复杂的事务,效率很低,绝对不适合高并发的场景。
|
|
|
+
|
|
|
+一般来说某个系统内部如果出现跨多个库的这么一个操作,是不合规的。如果你要操作别人的服务的库,你必须是通过调用别的服务的接口来实现,绝对不允许交叉访问别人的数据库。
|
|
|
+
|
|
|
+### 2、TCC强一致性方案
|
|
|
+
|
|
|
+TCC 的全称是:`Try`、`Confirm`、`Cancel`。
|
|
|
+
|
|
|
+- **Try 阶段**:这个阶段说的是对各个服务的资源做检测以及对资源进行 **锁定或者预留**。
|
|
|
+- **Confirm 阶段**:这个阶段说的是在各个服务中执行实际的操作。
|
|
|
+- **Cancel 阶段**:如果任何一个服务的业务方法执行出错,那么这里就需要 **进行补偿**,就是执行已经执行成功的业务逻辑的回滚操作。(把那些执行成功的回滚)
|
|
|
+
|
|
|
+这种方案说实话几乎很少人使用,但是也有使用的场景。因为这个**事务回滚实际上是严重依赖于你自己写逻辑来实现回滚和补偿**,会造成巨大的补偿代码量。
|
|
|
+
|
|
|
+### 3、可靠消息最终一致性方案
|
|
|
+
|
|
|
+基于 MQ 来实现事务。比如阿里的 RocketMQ 就支持消息事务。大概的意思就是:
|
|
|
+
|
|
|
+1. A 系统先发送一个 prepared 消息到 MQ,如果这个 prepared 消息发送失败那么就直接取消操作别执行了;
|
|
|
+2. 如果这个消息发送成功过了,那么接着执行本地事务,如果成功就告诉 MQ 发送确认消息,如果失败就告诉 MQ 回滚消息;
|
|
|
+3. 如果发送了确认消息,那么此时 B 系统会接收到确认消息,然后执行本地的事务;
|
|
|
+4. mq 会自动定时轮询所有 prepared 消息回调你的接口,问你,这个消息是不是本地事务处理失败了,所有没发送确认的消息,是继续重试还是回滚?一般来说这里你就可以查下数据库看之前本地事务是否执行,如果回滚了,那么这里也回滚吧。这个就是避免可能本地事务执行成功了,而确认消息却发送失败了。
|
|
|
+5. 这个方案里,要是系统 B 的事务失败了咋办?重试咯,自动不断重试直到成功,如果实在是不行,要么就是针对重要的资金类业务进行回滚,比如 B 系统本地回滚后,想办法通知系统 A 也回滚;或者是发送报警由人工来手工回滚和补偿。
|
|
|
+
|
|
|
+### 4、最大努力通知方案
|
|
|
+
|
|
|
+1. 系统 A 本地事务执行完之后,发送个消息到 MQ;
|
|
|
+2. 这里会有个专门消费 MQ 的最大努力通知服务,这个服务会消费 MQ 然后写入数据库中记录下来,或者是放入个内存队列也可以,接着调用系统 B 的接口;
|
|
|
+3. 要是系统 B 执行成功就 ok 了;要是系统 B 执行失败了,那么最大努力通知服务就定时尝试重新调用系统 B,反复 N 次,最后还是不行就放弃。
|
|
|
+
|
|
|
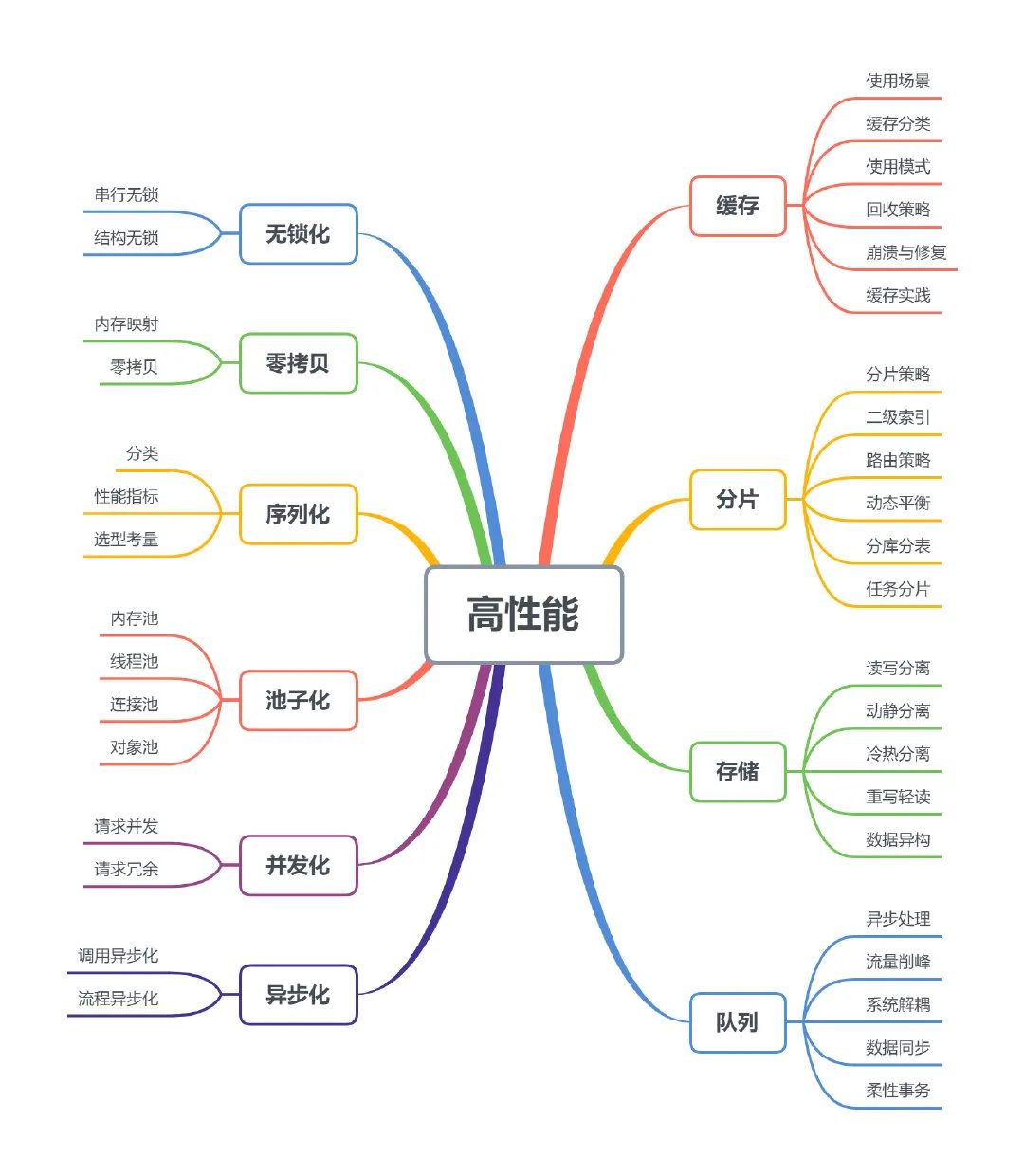
+## 如何设计一个高可用,高性能的系统?
|
|
|
+
|
|
|
+
|
|
|
+
|
|
|
+### 1 无锁化
|
|
|
+
|
|
|
+大多数情况下,多线程处理可以提高并发性能,但如果对共享资源的处理不当,严重的锁竞争也会导致性能的下降。面对这种情况,有些场景采用了无锁化设计,特别是在底层框架上。无锁化主要有两种实现,串行无锁和数据结构无锁。
|
|
|
+
|
|
|
+#### 1.1 串行无锁
|
|
|
+
|
|
|
+无锁串行最简单的实现方式可能就是单线程模型了,如 redis/Nginx 都采用了这种方式。在网络编程模型中,常规的方式是主线程负责处理 I/O 事件,并将读到的数据压入队列,工作线程则从队列中取出数据进行处理,这种半同步/半异步模型需要对队列进行加锁,如下图所示:
|
|
|
+
|
|
|
+
|
|
|
+
|
|
|
+上图的模式可以改成无锁串行的形式,当 MainReactor accept 一个新连接之后从众多的 SubReactor 选取一个进行注册,通过创建一个 Channel 与 I/O 线程进行绑定,此后该连接的读写都在同一个线程执行,无需进行同步。
|
|
|
+
|
|
|
+
|
|
|
+
|
|
|
+#### 1.2 结构无锁
|
|
|
+
|
|
|
+利用硬件支持的原子操作可以实现无锁的数据结构,很多语言都提供 CAS 原子操作(如 go 中的 atomic 包和 C++11 中的 atomic 库),可以用于实现无锁队列。
|
|
|
+
|
|
|
+### 2 零拷贝
|
|
|
+
|
|
|
+### 3 序列化
|
|
|
+
|
|
|
+当将数据写入文件、发送到网络、写入到存储时通常需要序列化(serialization)技术,从其读取时需要进行反序列化(deserialization),又称编码(encode)和解码(decode)。序列化作为传输数据的表示形式,与网络框架和通信协议是解耦的。如网络框架 taf 支持 jce、json 和自定义序列化,HTTP 协议支持 XML、JSON 和流媒体传输等。
|
|
|
+
|
|
|
+序列化的方式很多,作为数据传输和存储的基础,如何选择合适的序列化方式尤其重要。
|
|
|
+
|
|
|
+### 4 池子化
|
|
|
+
|
|
|
+池化恐怕是最常用的一种技术了,其本质就是通过创建池子来提高对象复用,减少重复创建、销毁的开销。常用的池化技术有**内存池、线程池、连接池、对象池**等。
|
|
|
+
|
|
|
+### 5 并发化
|
|
|
+
|
|
|
+#### 5.1 请求并发
|
|
|
+
|
|
|
+如果一个任务需要处理多个子任务,可以将没有依赖关系的子任务并发化,这种场景在后台开发很常见。如一个请求需要查询 3 个数据,分别耗时 T1、T2、T3,如果串行调用总耗时 T=T1+T2+T3。对三个任务执行并发,总耗时 T=max(T1,T 2,T3)。同理,写操作也如此。对于同种请求,还可以同时进行批量合并,减少 RPC 调用次数。
|
|
|
+
|
|
|
+#### 5.2 冗余请求
|
|
|
+
|
|
|
+冗余请求指的是同时向后端服务发送多个同样的请求,谁响应快就是使用谁,其他的则丢弃。这种策略缩短了客户端的等待时间,但也使整个系统调用量猛增,一般适用于初始化或者请求少的场景。公司 WNS 的跑马模块其实就是这种机制,跑马模块为了快速建立长连接同时向后台多个 ip/port 发起请求,谁快就用谁,这在弱网的移动设备上特别有用,如果使用等待超时再重试的机制,无疑将大大增加用户的等待时间。
|
|
|
+
|
|
|
+### 6 异步化
|
|
|
+
|
|
|
+对于处理耗时的任务,如果采用同步等待的方式,会严重降低系统的吞吐量,可以通过异步化进行解决。异步在不同层面概念是有一些差异的,在这里我们不讨论异步 I/O。
|
|
|
+
|
|
|
+#### 6.1 调用异步化
|
|
|
+
|
|
|
+在进行一个耗时的 RPC 调用或者任务处理时,常用的异步化方式如下:
|
|
|
+
|
|
|
+- **Callback**:异步回调通过注册一个回调函数,然后发起异步任务,当任务执行完毕时会回调用户注册的回调函数,从而减少调用端等待时间。这种方式会造成代码分散难以维护,定位问题也相对困难。
|
|
|
+
|
|
|
+- **Future**:当用户提交一个任务时会立刻先返回一个 Future,然后任务异步执行,后续可以通过 Future 获取执行结果。对 1.4.1 中请求并发,我们可以使用 Future 实现,伪代码如下:
|
|
|
+
|
|
|
+ ```java
|
|
|
+ //异步并发任务
|
|
|
+ Future<Response> f1 = Executor.submit(query1);
|
|
|
+ Future<Response> f2 = Executor.submit(query2);
|
|
|
+ Future<Response> f3 = Executor.submit(query3);
|
|
|
+
|
|
|
+ //处理其他事情
|
|
|
+ doSomething();
|
|
|
+
|
|
|
+ //获取结果
|
|
|
+ Response res1 = f1.getResult();
|
|
|
+ Response res2 = f2.getResult();
|
|
|
+ Response res3 = f3.getResult();
|
|
|
+ ```
|
|
|
+
|
|
|
+- CPS
|
|
|
+
|
|
|
+ (Continuation-passing style)可以对多个异步编程进行编排,组成更复杂的异步处理,并以同步的代码调用形式实现异步效果。CPS 将后续的处理逻辑当作参数传递给 Then 并可以最终捕获异常,解决了异步回调代码散乱和异常跟踪难的问题。Java 中的 CompletableFuture 和 C++ PPL 基本支持这一特性。典型的调用形式如下:
|
|
|
+
|
|
|
+ ```java
|
|
|
+ void handleRequest(const Request &req)
|
|
|
+ {
|
|
|
+ return req.Read().Then([](Buffer &inbuf){
|
|
|
+ return handleData(inbuf);
|
|
|
+ }).Then([](Buffer &outbuf){
|
|
|
+ return handleWrite(outbuf);
|
|
|
+ }).Finally(){
|
|
|
+ return cleanUp();
|
|
|
+ });
|
|
|
+ }
|
|
|
+ ```
|
|
|
+
|
|
|
+#### 6.2 流程异步化
|
|
|
+
|
|
|
+一个业务流程往往伴随着调用链路长、后置依赖多等特点,这会同时降低系统的可用性和并发处理能力。可以采用对非关键依赖进行异步化解决。如企鹅电竞开播服务,除了开播写节目存储以外,还需要将节目信息同步到神盾推荐平台、App 首页和二级页等。由于同步到外部都不是开播的关键逻辑且对一致性要求不是很高,可以对这些后置的同步操作进行异步化,写完存储即向 App 返回响应,如下图所示:
|
|
|
+
|
|
|
+
|
|
|
+
|
|
|
+### 7 缓存
|
|
|
+
|
|
|
+从单核 CPU 到分布式系统,从前端到后台,缓存无处不在。古有朱元璋“缓称王”而终得天下,今有不论是芯片制造商还是互联网公司都同样采取了“缓称王”(缓存称王)的政策才能占据一席之地。缓存是原始数据的一个复制集,其本质就是空间换时间,主要是为了解决高并发读。
|
|
|
+
|
|
|
+- **进程级缓存**:缓存的数据直接在进程地址空间内,这可能是访问速度最快使用最简单的缓存方式了。主要缺点是受制于进程空间大小,能缓存的数据量有限,进程重启缓存数据会丢失。一般通常用于缓存数据量不大的场景。
|
|
|
+- **集中式缓存**:缓存的数据集中在一台机器上,如共享内存。这类缓存容量主要受制于机器内存大小,而且进程重启后数据不丢失。常用的集中式缓存中间件有单机版 redis、memcache 等。
|
|
|
+- **分布式缓存**:缓存的数据分布在多台机器上,通常需要采用特定算法(如 Hash)进行数据分片,将海量的缓存数据均匀的分布在每个机器节点上。常用的组件有:Memcache(客户端分片)、Codis(代理分片)、Redis Cluster(集群分片)。
|
|
|
+- **多级缓存**:指在系统中的不同层级的进行数据缓存,以提高访问效率和减少对后端存储的冲击。以下图的企鹅电竞的一个多级缓存应用,根据我们的现网统计,在第一级缓存的命中率就已经达 94%,穿透到 grocery 的请求量很小。
|
|
|
+
|
|
|
+### 8 分片
|
|
|
+
|
|
|
+分片即将一个较大的部分分成多个较小的部分,在这里我们分为数据分片和任务分片。对于数据分片,在本文将不同系统的拆分技术术语(如 region、shard、vnode、partition)等统称为分片。分片可以说是一箭三雕的技术,将一个大数据集分散在更多节点上,单点的读写负载随之也分散到了多个节点上,同时还提高了扩展性和可用性。
|
|
|
+
|
|
|
+数据分片,小到编程语言标准库里的集合,大到分布式中间件,无所不在。如我曾经写过一个线程安全的容器以放置各种对象时,为了减少锁争用,对容器进行了分段,每个分段一个锁,按照哈希或者取模将对象放置到某个分段中,如 Java 中的 ConcurrentHashMap 也采取了分段的机制。分布式消息中间件 Kafka 中对 topic 也分成了多个 partition,每个 partition 互相独立可以比并发读写。
|
|
|
+
|
|
|
+* 一致性哈希
|
|
|
+* 分库分表
|
|
|
+* 任务分片,例如Map/Reduce
|
|
|
+* 动态平衡,例如kafka的rebalance
|
|
|
+
|
|
|
+### 9 存储
|
|
|
+
|
|
|
+任何一个系统,从单核 CPU 到分布式,从前端到后台,要实现各式各样的功能和逻辑,只有读和写两种操作。而每个系统的业务特性可能都不一样,有的侧重读、有的侧重写,有的两者兼备,本节主要探讨在不同业务场景下存储读写的一些方法论。
|
|
|
+
|
|
|
+#### 9.1 读写分离
|
|
|
+
|
|
|
+#### 9.2 动静分离
|
|
|
+
|
|
|
+#### 9.3 冷热分离
|
|
|
+
|
|
|
+#### 9.4 重写轻读
|
|
|
+
|
|
|
+### 10 队列
|
|
|
+
|
|
|
+在系统应用中,不是所有的任务和请求必须实时处理,很多时候数据也不需要强一致性而只需保持最终一致性,有时候我们也不需要知道系统模块间的依赖,在这些场景下队列技术大有可为。
|
|
|
+
|
|
|
+## 如何优化一个慢SQL?
|
|
|
+
|
|
|
+在慢SQL的优化过程中,可以从以下五个角度去进行思考优化:**SQL优化、资源占用、业务改造、数据减少、源头替换**。
|
|
|
+
|
|
|
+### 1. sql优化
|
|
|
+
|
|
|
+SQL语句的优化方式主要是通过选择合适的索引、优化查询语句、避免全表扫描等提高查询效率,减少慢SQL的出现
|
|
|
+
|
|
|
+* join优化,小表驱动大表,大表加索引
|
|
|
+* in & exists
|
|
|
+
|
|
|
+in执行流程:查询子查询的表且内外表有关联时,先执行内层表的子查询,然后将内表和外表做一个笛卡尔积,然后按照条件进行筛选,得到结果集。所以相对内表比较小的时候,in的速度较快
|
|
|
+
|
|
|
+exists执行流程:指定一个子查询,检测行的存在。遍历循环外表,然后看外表中的记录有没有和内表的数据一样的,匹配上就将结果放入结果集中
|
|
|
+
|
|
|
+* 建议使用not exists代替not in,not in使用的是全表扫描没有用到索引;而not exists在子查询依然能用到表上的索引
|
|
|
+* 使用索引
|
|
|
+
|
|
|
+### 2. 资源占用
|
|
|
+
|
|
|
+- 锁资源等待:在读写很热的表上,通常会发生锁资源争夺,从而导致慢查询的情况
|
|
|
+ - 谨慎使用for update
|
|
|
+ - 增删改尽量使用到索引
|
|
|
+ - 降低并发,避免对同一条数据进行反复修改
|
|
|
+- 网络波动:往客户端发送数据时发生网络波动导致的慢查询
|
|
|
+- 硬件配置:CPU利用率高,磁盘IO经常满载,导致慢查询
|
|
|
+
|
|
|
+在高并发、高流量下,数据库所在机器的负载load过高也会导致SQL整体执行时间过长,这时可能需要从机器和实例的分配,分布式部署,分库分表,读写分离等角度进行优化
|
|
|
+
|
|
|
+### 3. 业务改造
|
|
|
+- 是不是真的需要全部查出来,还是取其中的top N就能够满足需求了
|
|
|
+- 查询条件过多的情况下,能否前端页面提示限制过多的查询条件的使用
|
|
|
+- 针对实时导出的数据,涉及到实时查DB导出大量数据时,限制导出数据量 or 走T+1的离线导出是不是也是可以的
|
|
|
+- 现在业务上需要做数据搜索,使用了 LIKE “%关键词%” 做全模糊查询,从而导致了慢SQL。是不是可以让业务方妥协下,最右模糊匹配,这样就可以利用上索引了
|
|
|
+
|
|
|
+### 4. 源头替换
|
|
|
+
|
|
|
+Mysql并不是任何的查询场景都是适合的,如需要支持全模糊搜索时,全模糊的like是无法走到索引的。同时结合数据本身的生命周期,对于热点数据,可以考虑存储到缓存解决。因此针对不适合mysql数据源的情况,我们需要替代新的存储介质
|
|
|
+
|
|
|
+- 有like的全模糊的查询,比如基于文本内容去查订单信息,需要接搜索引擎解决
|
|
|
+- 有热点数据的查询,考虑是否要接缓存解决
|
|
|
+- 针对复杂条件的海量数据查询,可以考虑切换到OLAP(Online Analytical Processing),可以考虑接Hybrid DB或ADB通道
|
|
|
+- 有些场景Mysql不适用,需要用K-V的数据库,HBASE等列式存储的存储引擎
|
|
|
+
|
|
|
+### 5. 数据减少
|
|
|
+
|
|
|
+QL本身的性能已经到达极限了,但是耗时仍然很长,可能由于数据量或索引数据都比较大了。因此需要从数据量级减少的角度去处理
|
|
|
+
|
|
|
+- 使用分库分表。由于单表的数据量过大,例如达到千万级别的数据了,需要使用分库分表技术拆分后减轻单库单表的单点压力
|
|
|
+- 定时清理终态数据。针对已经状态为终态的业务单据或明显信息,可以使用idb历史数据清理的方式配置定时自动清理。如针对我们的仓储库存操作明细为完结状态的数据,我们只保留最近1天的数据在db中,其他直接删除,减少db查询压力
|
|
|
+- 统计类查询可以单独维护汇总数据表。参考数据仓库中的数据分层设计,基于明细数据,抽出一张指标汇总表,或7天/15天等的视图数据进行预计算。此类汇总表数据量级相比明细表下降很多,从而避免直接根据大量明细查询聚合造成慢sql
|
|
|
+
|
|
|
+## 如何设计B站?
|
|
|
+
|
|
|
+* 用户推荐方向:可以从视频分类,然后按照用户标签去分析。
|
|
|
+* 缓存,可以用本地缓存,类似map/reduce批量去更新
|

{kind=link}
{kind=link}

{kind=link}

{kind=link}
