
променени са 62 файла, в които са добавени 1431 реда и са изтрити 15 реда
+ 1
- 1
算法/排序算法/基本排序算法.md
|
||
|
||
|
||
|
||
|
||
|
||
+ 6
- 0
面经/2023年暑期实习/百度.md
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 5
- 0
面经/工作/秋招.md
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 1
- 1
面经/问答/JVM.md
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 251
- 0
面经/问答/Mysql.md
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
BIN
面经/问答/assets/2306520394.png
{kind=link}
BIN
面经/问答/assets/24-先来先服务.jpg
{kind=link}

BIN
面经/问答/assets/25-最短作业优先算法.jpg
{kind=link}

BIN
面经/问答/assets/26-响应比公式.jpg
{kind=link}

BIN
面经/问答/assets/27-时间片轮询.jpg
{kind=link}
BIN
面经/问答/assets/28-多级队列.jpg
{kind=link}
BIN
面经/问答/assets/30c2c70721c12f9c140358fbdc5f2282.png
{kind=link}
BIN
面经/问答/assets/3a6cb4e3f27241d3b09b4766bb0b1124.png
{kind=link}
BIN
面经/问答/assets/9ebde5c11ad69447314c216acf188fc8.png
{kind=link}

BIN
面经/问答/assets/a3e7d217ecb825e94bdc577a467eb29d.png
{kind=link}
BIN
面经/问答/assets/b5681d905102439aa1a40412100da566.png
{kind=link}
BIN
面经/问答/assets/c55029a32a6448d9aa35bb3de6efcecatplv-k3u1fbpfcp-zoom-in-crop-mark4536000.awebp
BIN
面经/问答/assets/d528bae6fcec2357ba2eb8f324ad9fd5.png
{kind=link}
BIN
面经/问答/assets/d565806a3b7c4735859befbcdad5a105.png
{kind=link}
BIN
面经/问答/assets/dba2bc3af0938d2c087f85acc191fd3f.png
{kind=link}
BIN
面经/问答/assets/dbb57b8d6071d011d05eeadd93269e13.png
{kind=link}
BIN
面经/问答/assets/e94e504adc5a75a2d7f562dc44166511.png
{kind=link}

BIN
面经/问答/assets/ec5c8e28d3ea308c6db2ac991a12ea80.png
{kind=link}
BIN
面经/问答/assets/f109a45fe4904726b11fd36422f4abactplv-k3u1fbpfcp-zoom-in-crop-mark4536000.awebp
BIN
面经/问答/assets/image-20210914195129983.png
{kind=link}
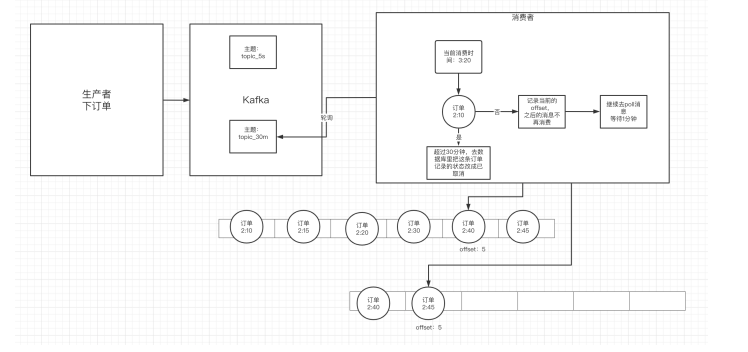
BIN
面经/问答/assets/image-20230726214326341.png
{kind=link}
BIN
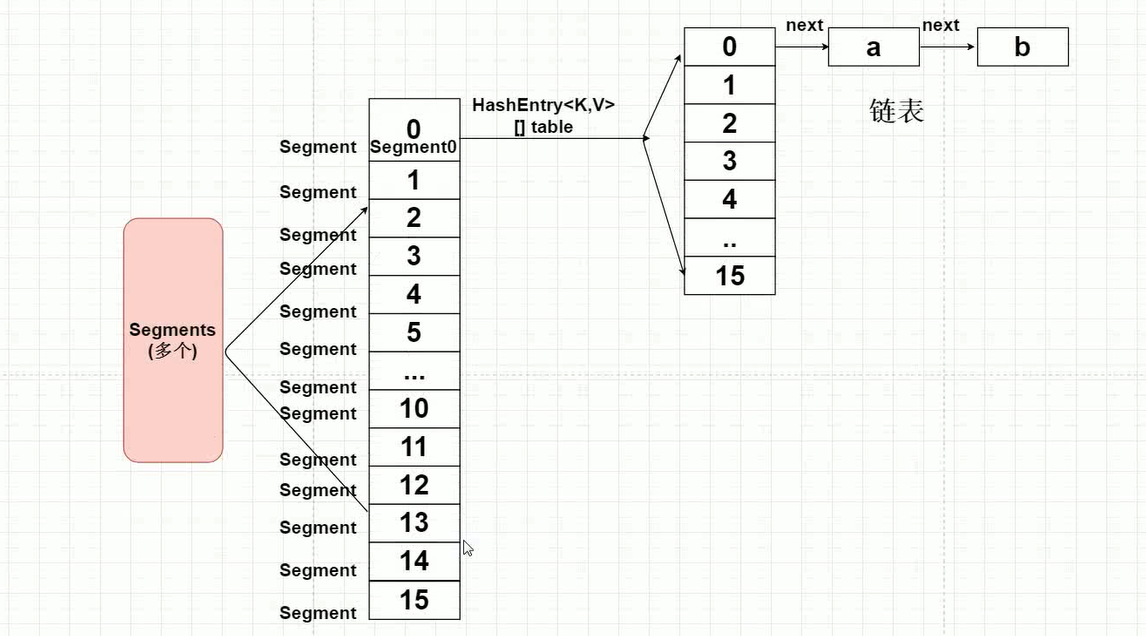
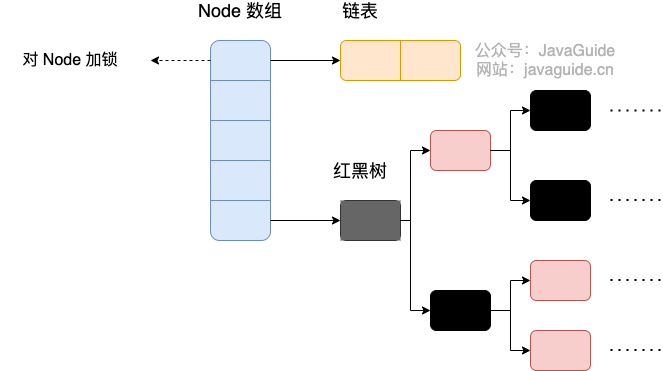
面经/问答/assets/java8_concurrenthashmap.png
{kind=link}
BIN
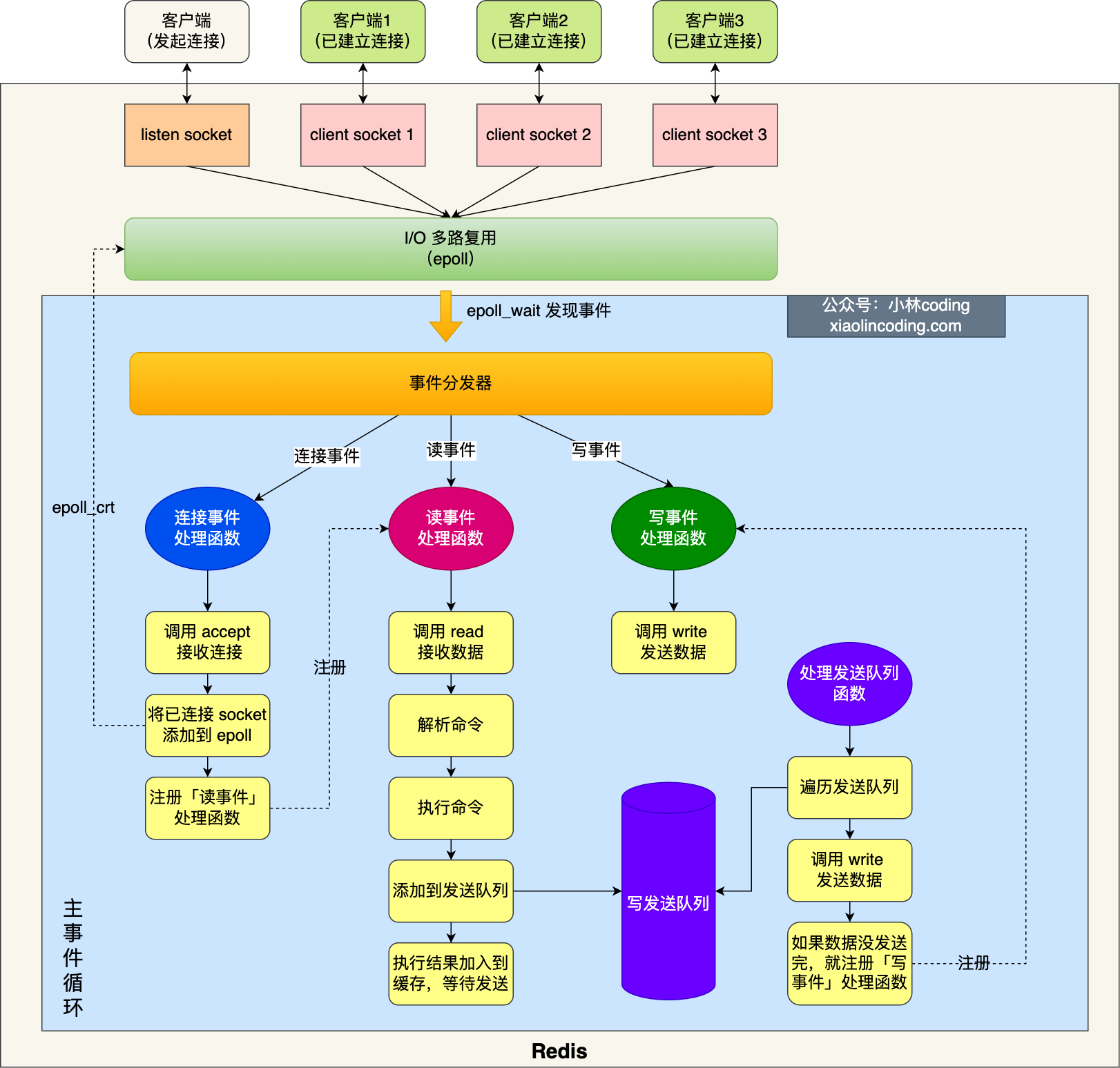
面经/问答/assets/redis单线程模型.drawio.png
{kind=link}
BIN
面经/问答/assets/redologbuf.webp
{kind=link}
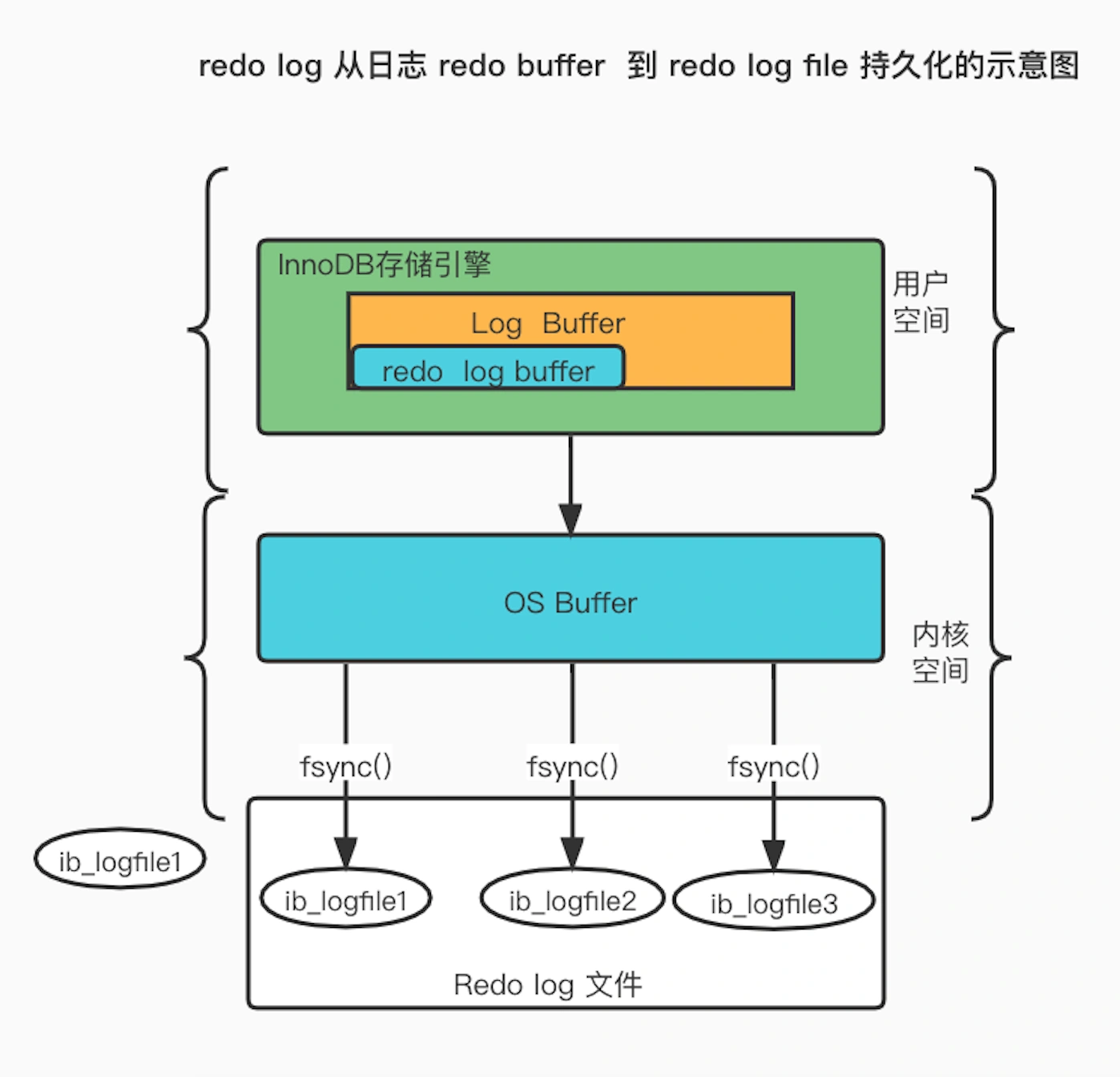
BIN
面经/问答/assets/senfile-零拷贝.png
{kind=link}
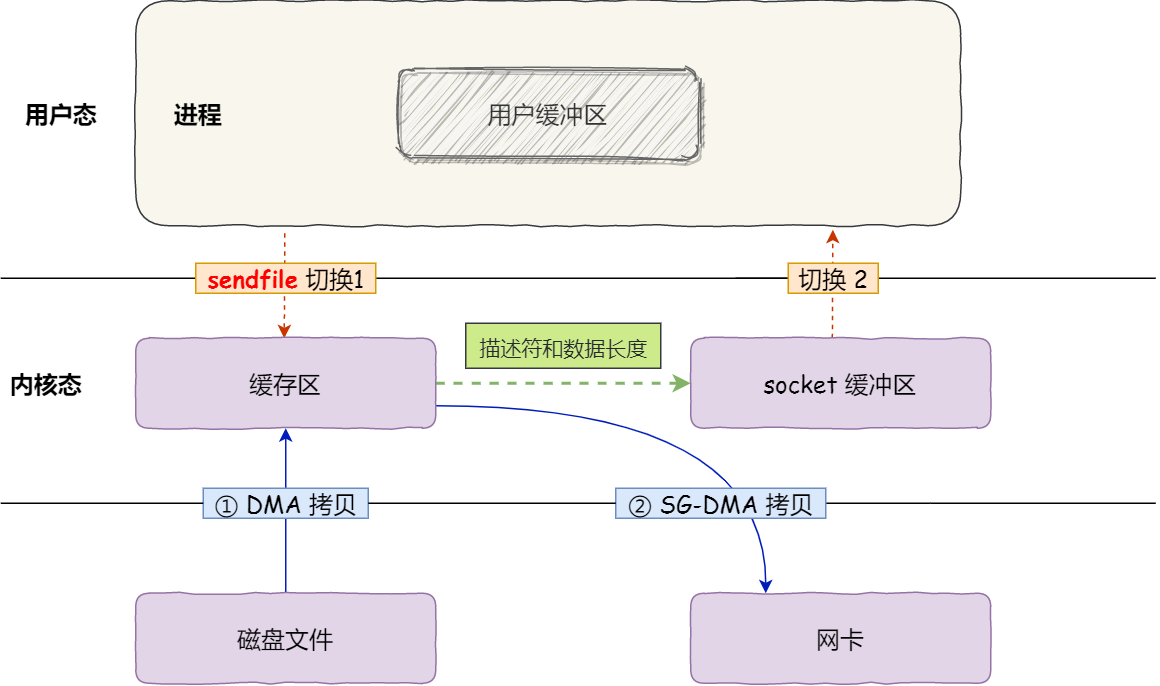
BIN
面经/问答/assets/v2-3ab6401c24be71551d1138762ed1a307_720w.webp
{kind=link}
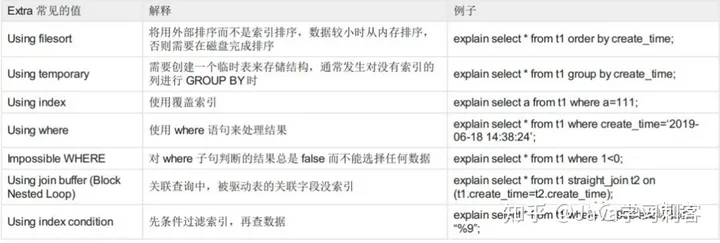
BIN
面经/问答/assets/v2-4c45bde8970caa0205d64b50095169c4_720w.webp
{kind=link}

BIN
面经/问答/assets/v2-8a6a18065863900773f1491c82af4884_720w.webp
{kind=link}
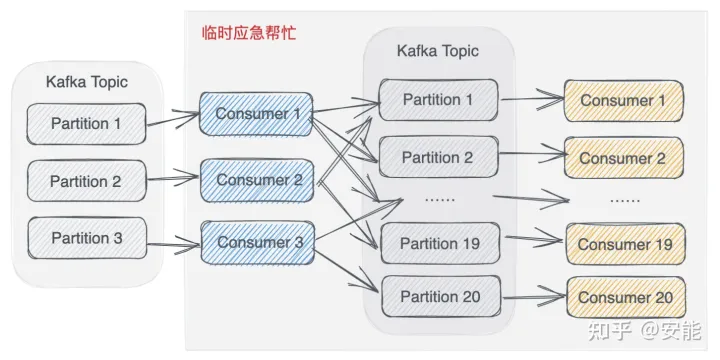
BIN
面经/问答/assets/v2-98b72fd8e29df55aecdafb8deff0312f_720w.webp
{kind=link}

BIN
面经/问答/assets/v2-cce29042ec33e8a9724ef70da24b8aca_720w.webp
{kind=link}

BIN
面经/问答/assets/wal.png
{kind=link}
BIN
面经/问答/assets/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQ1NjczMzY3,size_16,color_FFFFFF,t_70#pic_center-16899533239744.png
{kind=link}

BIN
面经/问答/assets/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQ1NjczMzY3,size_16,color_FFFFFF,t_70#pic_center.png
{kind=link}

BIN
面经/问答/assets/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3UwMTAwMjIxNTg=,size_16,color_FFFFFF,t_70.png
{kind=link}

BIN
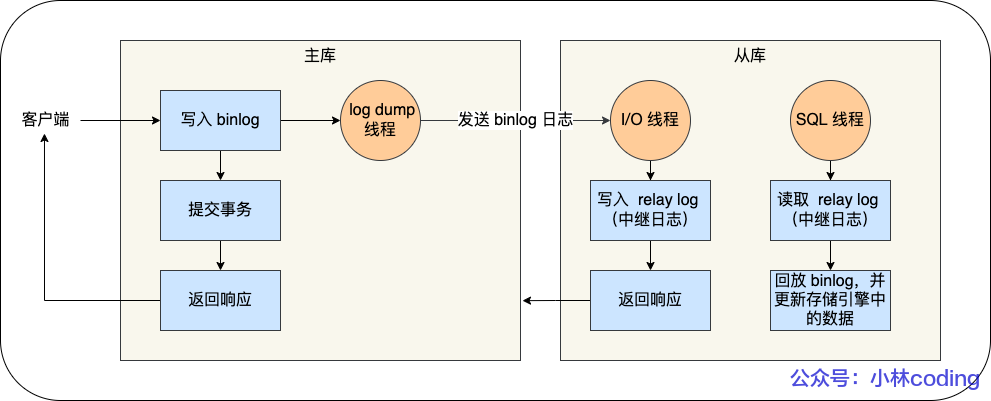
面经/问答/assets/主从复制过程.drawio.png
{kind=link}
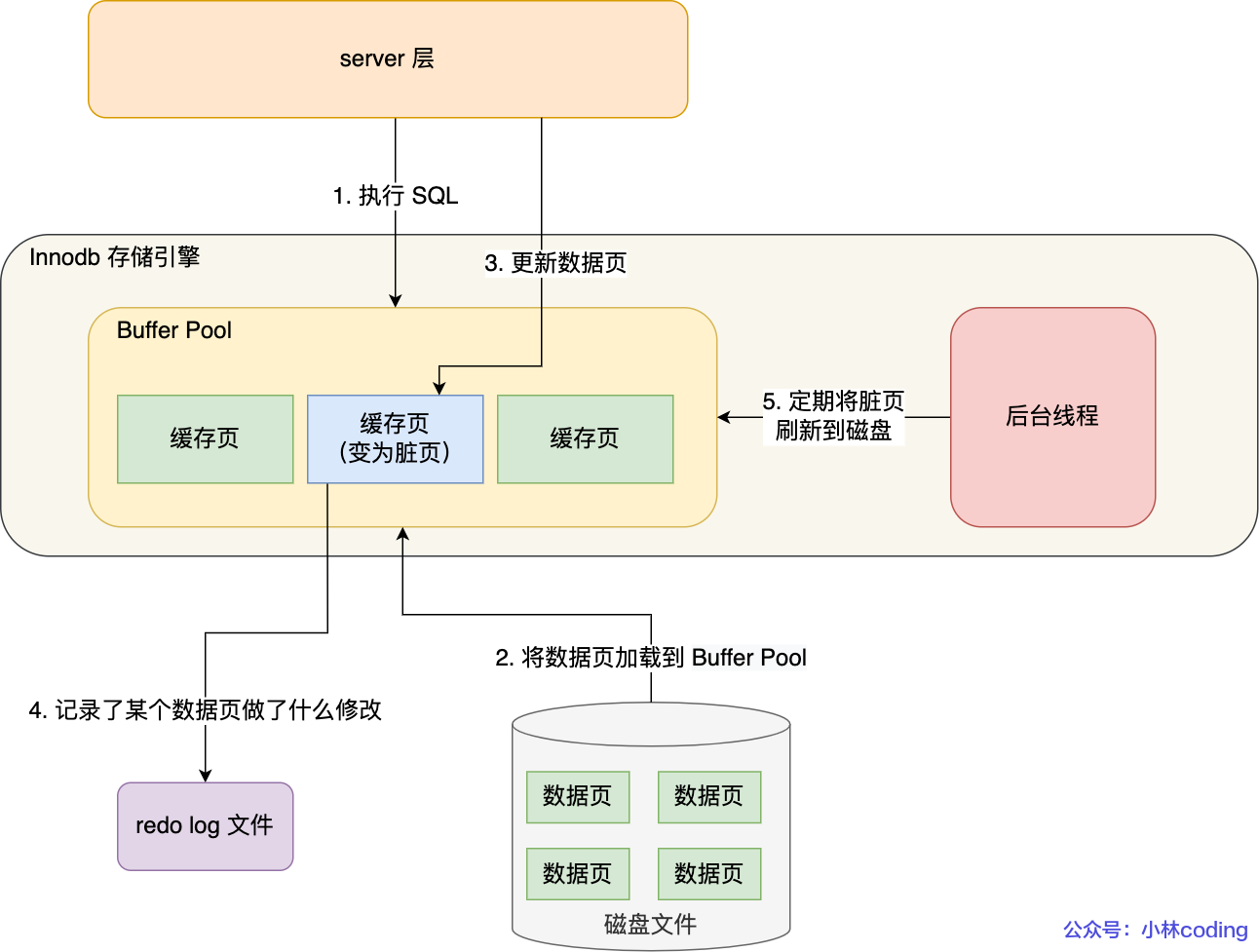
BIN
面经/问答/assets/事务恢复.png
{kind=link}
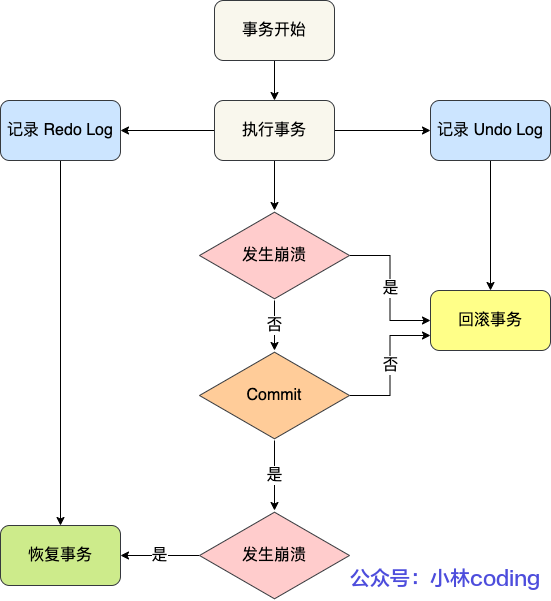
BIN
面经/问答/assets/后台线程.jpg
{kind=link}
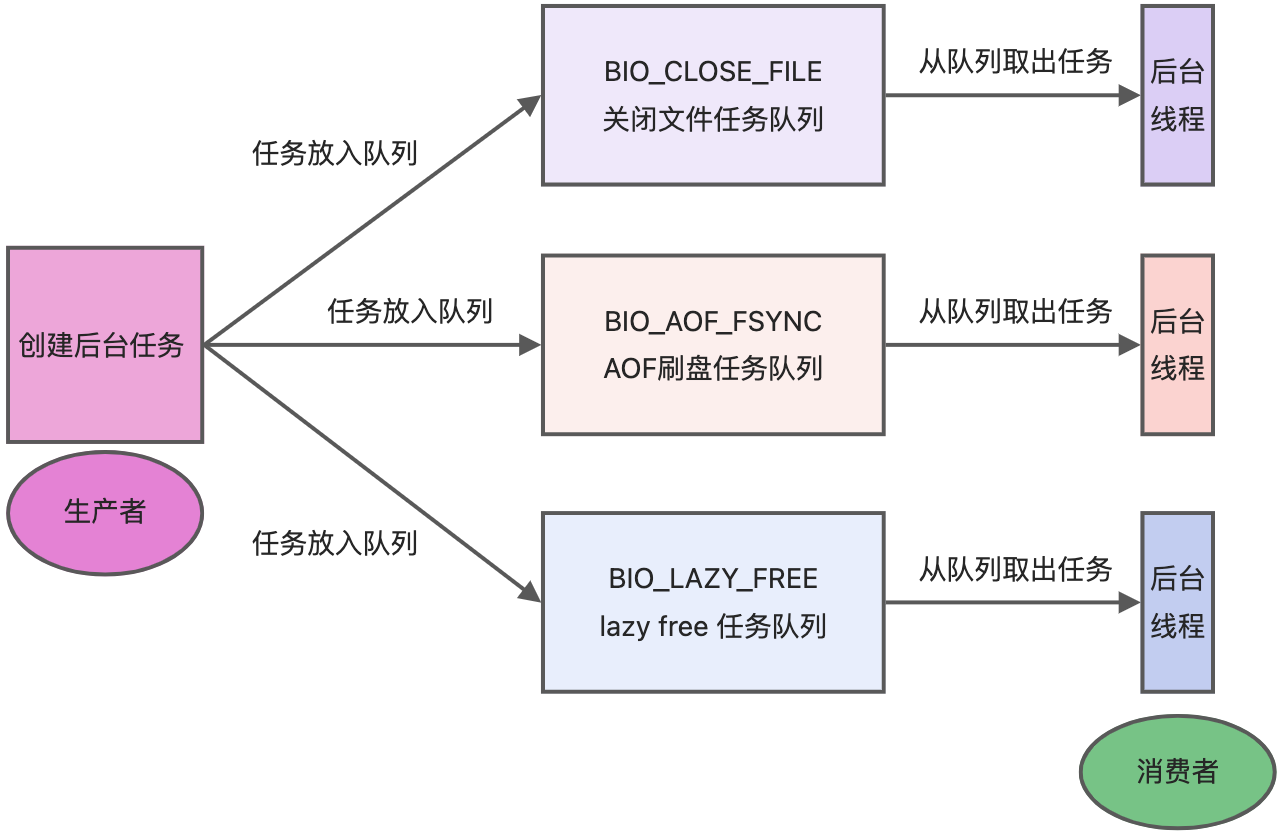
BIN
面经/问答/assets/回滚事务.png
{kind=link}
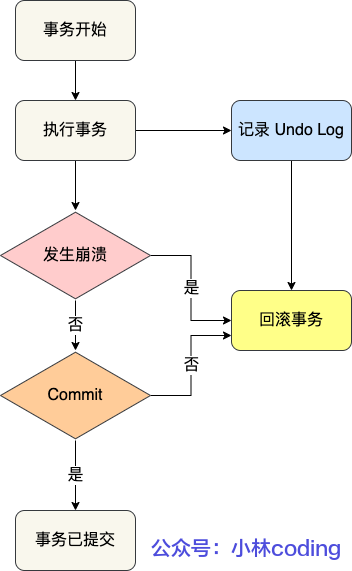
BIN
面经/问答/assets/版本链.png
{kind=link}

BIN
面经/问答/assets/磁盘调度-C-LOOK算法.png
{kind=link}
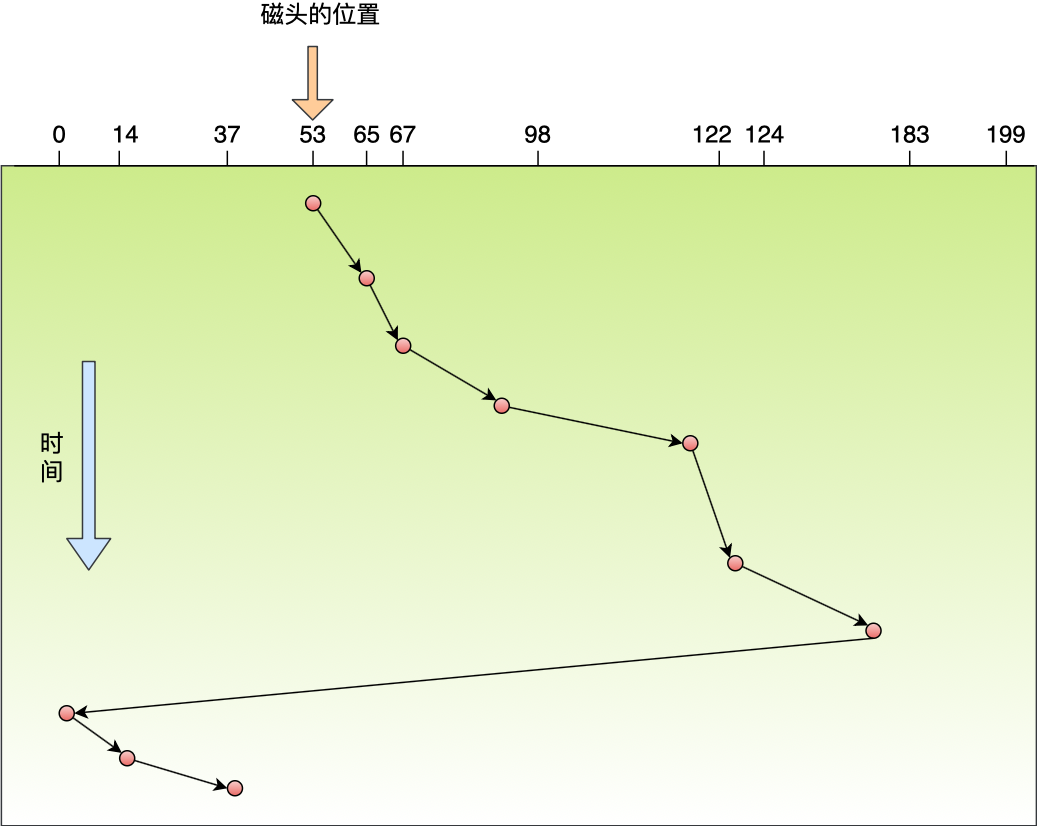
BIN
面经/问答/assets/磁盘调度-C-SCAN算法.png
{kind=link}
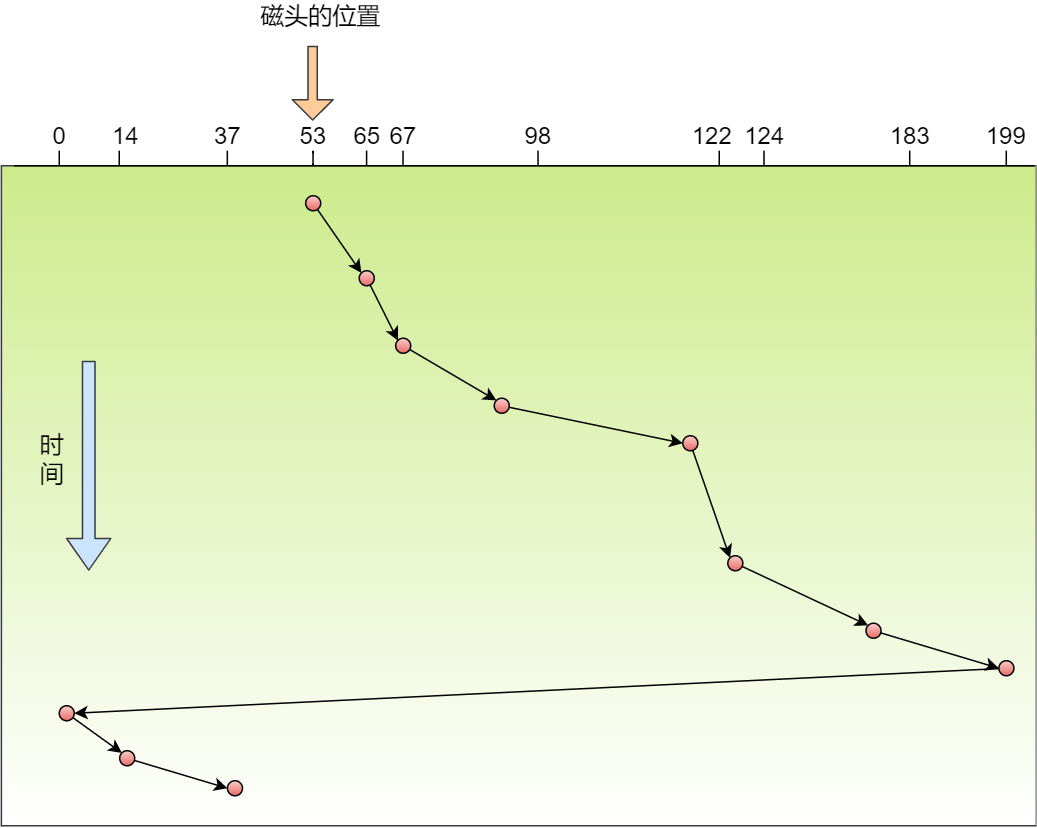
BIN
面经/问答/assets/磁盘调度-LOOK算法.png
{kind=link}
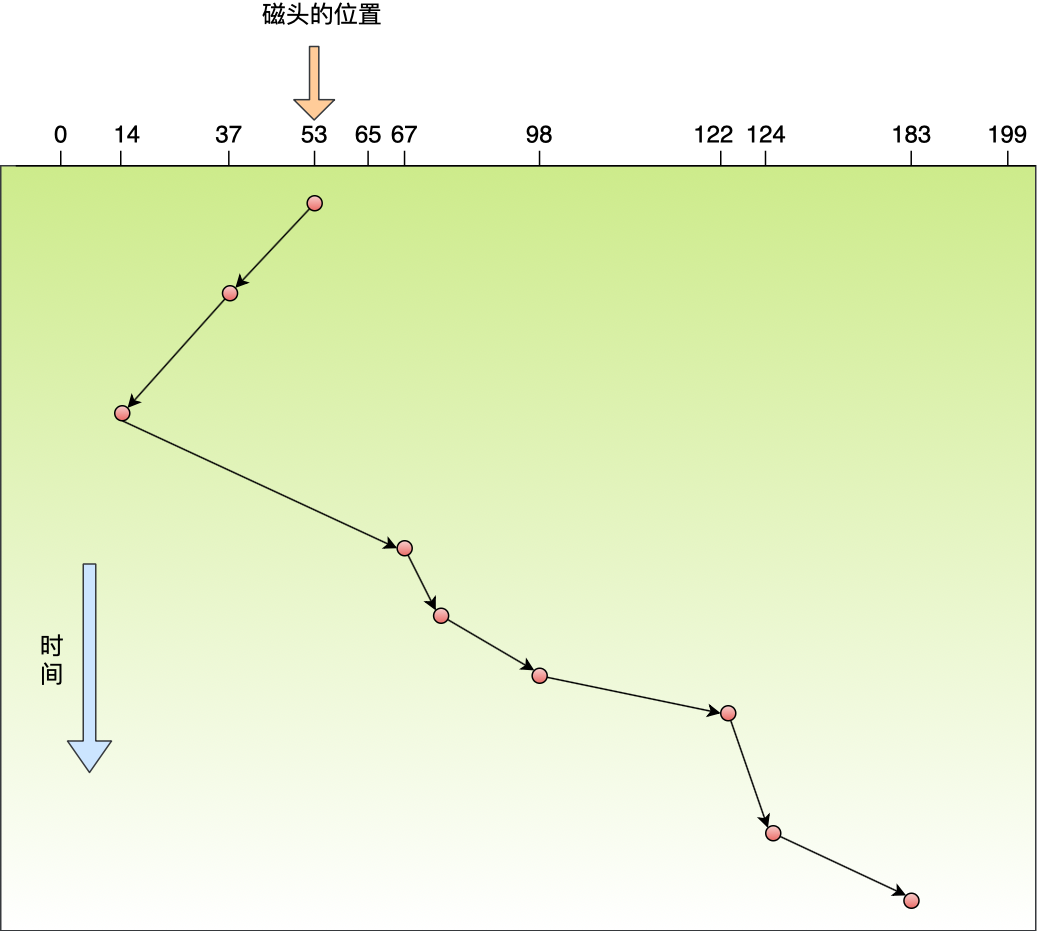
BIN
面经/问答/assets/磁盘调度-先来先服务.png
{kind=link}
BIN
面经/问答/assets/磁盘调度-扫描算法.png
{kind=link}
BIN
面经/问答/assets/磁盘调度-最短寻道时间优先.png
{kind=link}
BIN
面经/问答/assets/缓冲池.drawio.png
{kind=link}
+ 158
- 0
面经/问答/kafka.md
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 161
- 1
面经/问答/redis.md
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 87
- 1
面经/问答/spring.md
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 86
- 0
面经/问答/基础.md
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 21
- 4
面经/问答/并发编程.md
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 269
- 4
面经/问答/操作系统.md
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 43
- 0
面经/问答/智力问题.md
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 105
- 2
面经/问答/计网.md
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 155
- 0
面经/问答/集合.md
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 20
- 1
面经/项目/中煤项目.md
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 62
- 0
面经/项目/项目.md
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||